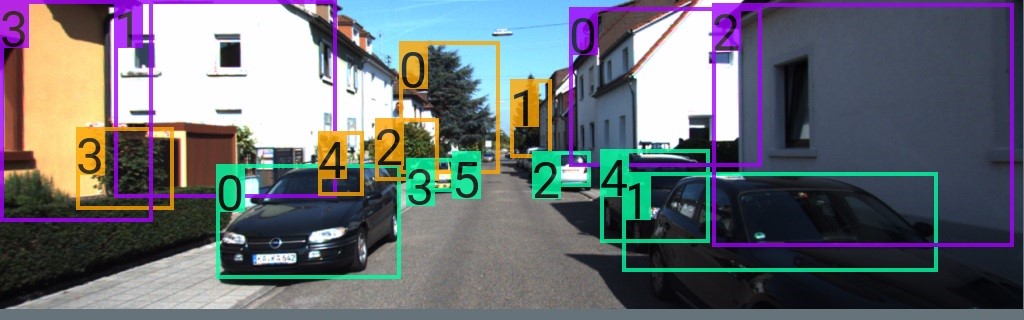
Manually annotating training data is laborious, and time-consuming. This means that training deep networks for computer vision tasks typically requires an enormous amount of labeled training data, which can be expensive and difficult to obtain. To help make deep learning more accessible, researchers from NVIDIA have introduced a structured domain randomization system to help developers train and refine their deep networks on synthetic data.
“Synthetic data is an attractive alternative because data annotation is essentially free,” the researchers stated in their paper.
To generate the synthetic data, the team used an approach called Structured Domain Randomization (SDR). This is a generalized technique for procedurally generating synthetic random images that preserve the structure or context of the problem at hand.
“Our methodology uses only synthetic data generated by SDR,” the team said. “We show that the results from this process not only outperform other approaches to generating synthetic data, but also real data from a different domain.”

Images generated by SDR can be used to train a neural network for perception tasks such as object detection on real images.
When generating these synthetic scenes the team randomizes the objects created in the scene including lanes, cars pedestrians, road signs, and sidewalks. For each object, its position, texture, shape, and color are randomized but only within realistic ranges. The technique also randomizes lighting parameters such as the time of day and image saturation.
The video above shows detection results on the KITTI benchmark, after training only in simulation.
| Dataset | Type | Size | Easy | Moderate | Hard |
| DR | synth | 25k | 56.8 | 38.0 | 23.9 |
| SDR (ours) | synth | 25k | 69.6 | 65.8 | 52.5 |
| BDD100K | real | 70k | 59.7 | 54.3 | 45.6 |
| KITTI | real | 6k | 85.1 | 88.3 | 88.8 |
Comparison of Faster-RCNN trained on synthetic data (DR, SDR) or real data (BDD100K, KITTI). Shown are AP@0.7 IOU for vehicle detection from a subset of 1,500 images from the real-world KITTI dataset. Although it is difficult for synthetic data to outperform real data from the same distribution as the test set (KITTI), our SDR approach nevertheless outperforms real data from another distribution (BDD100K).
For experimentation, the team used NVIDIA Tesla V100 GPUs on the NVIDIA SATURNV supercomputer.
The network detects objects in a scene on both videos and in still images with high confidence. This is remarkable because the network has never seen a real image during training.
| Dataset | Size | Easy | Moderate | Hard |
| VKITTI clones | 2.2k | 49.6 | 44.8 | 33.6 |
| VKITTI | 21k | 70.3 | 53.6 | 39.9 |
| Sim 200k | 200k | 68.0 | 52.6 | 42.1 |
| DR | 25k | 56.7 | 38.8 | 24.0 |
| SDR (ours) | 25k | 77.3 | 65.6 | 52.2 |
Comparison of Faster-RCNN trained on various synthetic datasets. Shown are AP@0.7 IOU for detecting vehicles on the entire real-world KITTI dataset consisting of 7,500 images.
SDR data can also be used to pre-train detection networks that are later fine-tuned with real data.
The team also tested the their network on the Cityscapes dataset, showing that the SDR trained networking generalizes well across multiple real-world domains.
In future research, the team says they will study SDR for detecting multiple object classes, semantic segmentation, instance segmentation and other computer vision problems
Read more >