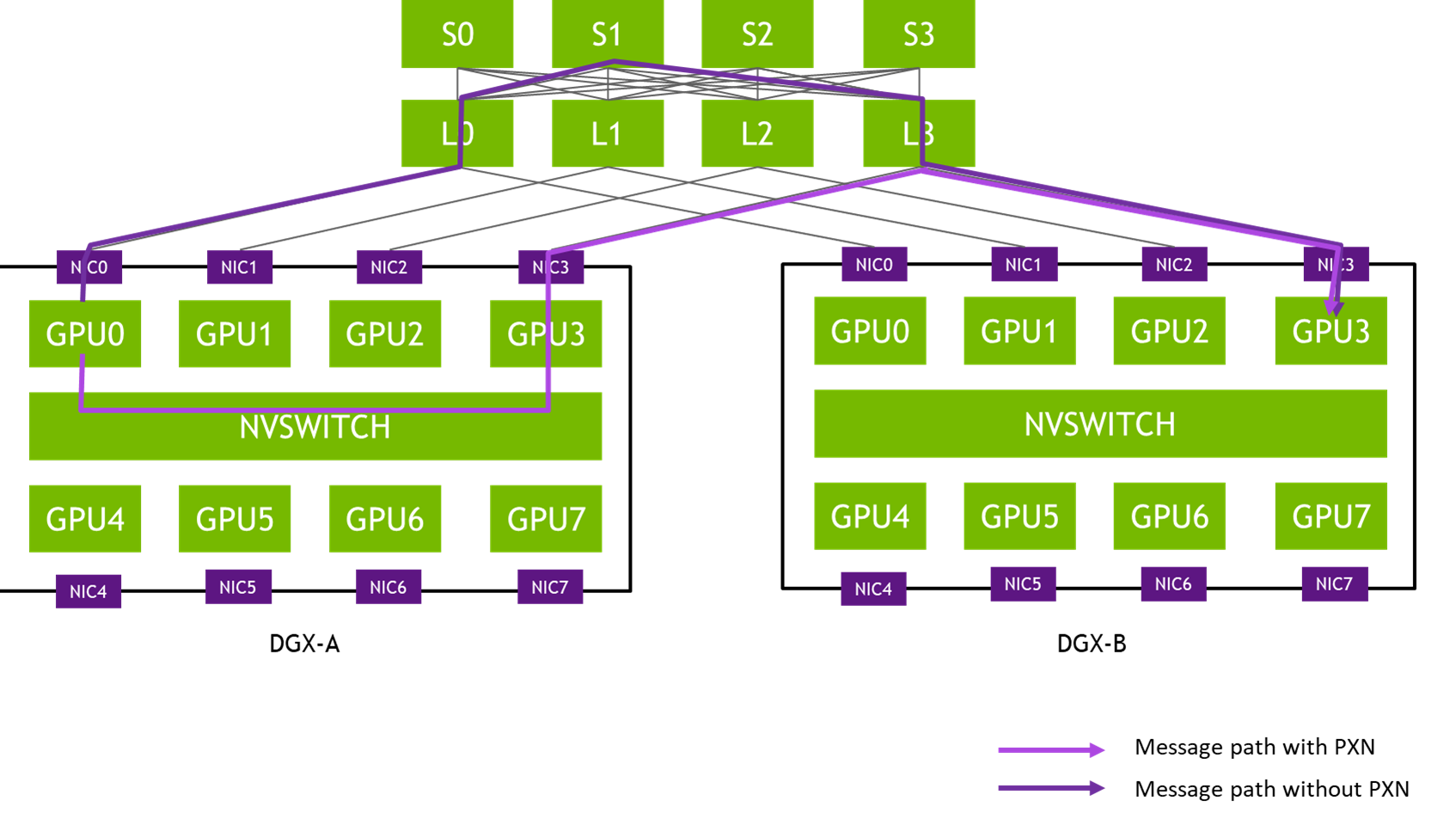
Today’s modern-day machine learning data centers require complex computations and fast, efficient data delivery. The NVIDIA Mellanox Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) takes advantage of the in-network computing capabilities in the NVIDIA Mellanox Quantum switch, dramatically improving the performance of distributed machine learning workloads.
SHARP technology improves upon the performance of MPI and Machine Learning collective operations by offloading collective operations from the CPU to the network and eliminating the need to send data multiple times between endpoints.
This innovative approach decreases the amount of data traversing the network as aggregation nodes are reached, and dramatically reduces collective operations time.