
Many may not know, NVIDIA is a significant contributor to the open-source deep learning community. How significant? Let’s reflect and explore the highlights and volume of activity from last year.
NVIDIA and Deep Learning Community
The deep learning frameworks team at NVIDIA is focused on directly improving and accelerating the deep learning communities’ frameworks.
We work closely with the deep learning open-source community as well as the framework development teams of widely used frameworks, such as Google’s TensorFlow, Facebook’s PyTorch and Caffe2, Apache Software Foundation’s MXNet, Microsoft’s Cognitive Toolkit, University of Montreal’s Theano as well as NVIDIA’s NVCaffe, which is an open-source fork of the original Caffe from BVLC.
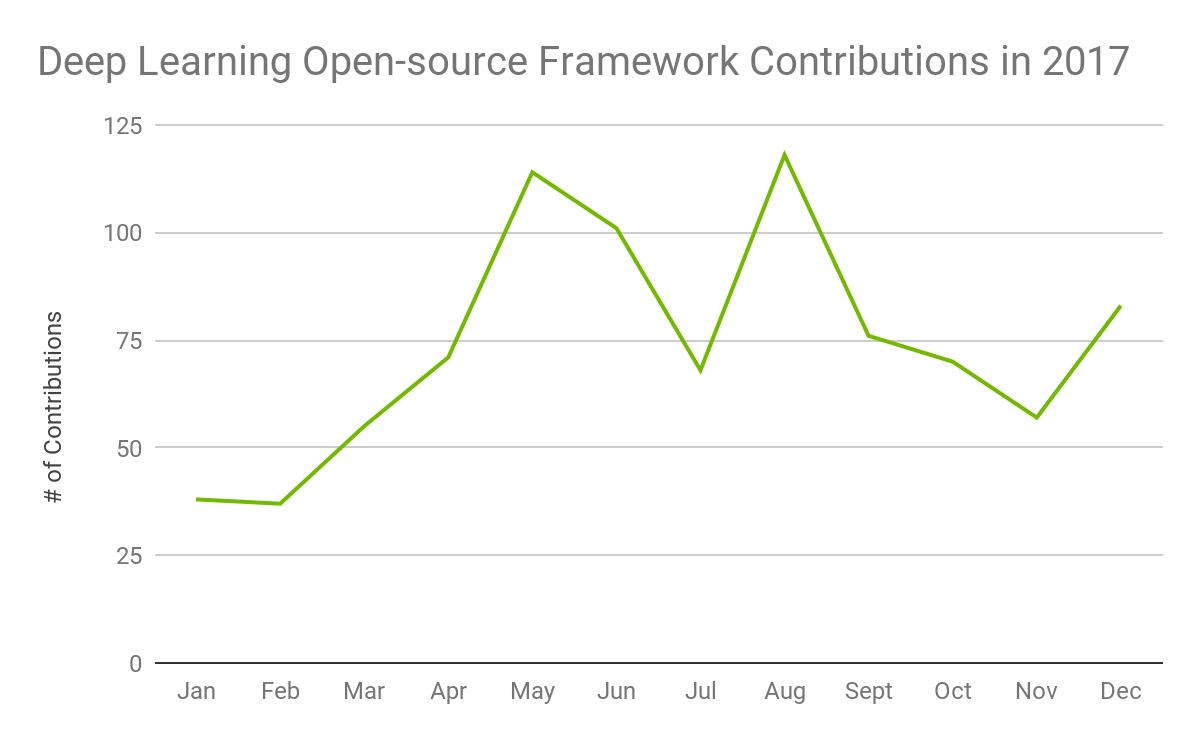
Given the computationally intensive workload for training tasks in deep learning, NVIDIA GPUs have been critical to the progress and success of the deep learning community. Throughout 2017, the NVIDIA deep learning frameworks team has been actively involved in direct collaboration with all of these framework groups and have made significant contributions that improved the frameworks’ ease of use and performance. The contributions range from larger efforts, such as open-sourcing new networks based on newly published research to smaller efforts, such as responding to ad-hoc community implementation questions. As illustrated in Figure 1, there were 844 total contributions in 2017, averaging 74 per month, from our deep learning frameworks team.
In this post, we’ll highlight our key contributions to the open-source deep learning community in 2017.
Contribution Highlights
In no specific order, below are the top highlights of our direct contributions to each of the deep learning frameworks from 2017:
MXNet
 MXnet is a deep learning framework designed for both efficiency and flexibility that allows you to mix the flavors of symbolic programming and imperative programming to maximize efficiency and productivity.
MXnet is a deep learning framework designed for both efficiency and flexibility that allows you to mix the flavors of symbolic programming and imperative programming to maximize efficiency and productivity.
We contributed the first public prototype of an MXNet to ONNX converter, allowing MXNet users to convert their trained models into ONNX format. ONNX provides an open source format for AI models allowing interoperability between deep learning frameworks, so that researchers and developers can exchange ONNX models between frameworks for training or deployment to inference engines, such as NVIDIA’s TensorRT.
Using the from_mxnet() function, MXNet users can specify the input model file (model_file) with the respective parameter file and the output ONNX file (onnx_file).
In example test_convert_lenet5.py, outputting MXNet model (model_file) to ONNX (onnx_file):
model = from_mxnet(model_file, params_file, [1, 1, 28, 28], np.float32, log=True)
with open(onnx_file, "wb") as f:
serialized = model.SerializeToString()
f.write(serialized)
print("\nONNX file %s serialized to disk" % onnx_file)
Our team also contributed the first GPU optimized MXNet NMT seq2seq network, allowing MXNet users access to the first native seq2seq network using a NMT (Neural Machine Translation) model. The general seq2seq network architecture is a very successful approach to many language-based tasks, such as text summarization, speech-to-text, text-to-speech, natural language understanding, and translation. NMT is a model implementation focusing on text-to-text translation between languages. For more on seq2seq, read some of the original research papers: Sequence to Sequence Learning with Neural Networks and Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation.
The provided NMT seq2seq model can be used for training with one simple command:
python seq2seq_bucketing.py --num-layers 2 --num-embed 500 --num-hidden 500 --optimizer adam --disp-batches 1 --gpus 0,1 --num-epochs 1 --batch-size 256
Caffe2
 Caffe2 is a deep learning framework enabling simple and flexible deep learning. Built on the original Caffe, Caffe2 is designed with expression, speed, and modularity in mind, allowing for a more flexible way to organize computation.
Caffe2 is a deep learning framework enabling simple and flexible deep learning. Built on the original Caffe, Caffe2 is designed with expression, speed, and modularity in mind, allowing for a more flexible way to organize computation.
We worked closely with the Caffe2 team at Facebook to implement support for the latest performance enhancement, NVIDIA Tensor Cores (Mixed-precision training with floating point 16), which is available for all users of the NVIDIA Volta GPU. NVIDIA Tensor Cores support allows reduced training times with similar accuracy, as detailed in our mixed-precision training blog. The multiple pull requests that we submitted and were accepted to enable Tensor Core support are available in the Caffe2 repository for reference.
In the Caffe2 GitHub repo for resnet50_trainer.py, there are two flags, –dtype float16 and –enable-tensor-core, which when added enable mixed-precision training using floating point 16 (FP16) and Tensor Cores, as shown:
python caffe2/python/examples/resnet50_trainer.py --train_data <path> --test_data <path> --num-gpus <int> --batch-size <int> --dtype float16 --enable-tensor-core --cudnn_workspace_limit_mb 1024 --image_size 224
In Listing 4 is an example workflow, similar to what’s provided in this network generation segment, of a convolutional network with mixed-precision training showing the specific functions of weight and bias initialization supporting floating point 16 for calculation, which is accelerated on NVIDIA Tensor Cores, while the final fully connected layer converts back to floating point 32 (FP32).
def createModelOps(model, loss_scale):
with brew.arg_scope([brew.conv, brew.fc],
WeightInitializer=pFP16Initializer,
BiasInitializer=pFP16Initializer):
conv1 = brew.conv(model, 'data', 'conv1', ...)
pool1 = brew.max_pool(model, conv1, 'pool1', ...)
conv2 = brew.conv(model, pool1, 'conv2', ...)
pool2 = brew.max_pool(model, conv2, 'pool2', ...)
fc3 = brew.fc(model, pool2, 'fc3', ...)
relu3 = brew.relu(model, fc3, 'relu3')
fc4 = brew.fc(model, relu3, 'fc4', ...)
fc4 = model.HalfToFloat(fc4, "fc4_fp32")
TensorFlow
 TensorFlow is a software library for numerical computation using data flow graphs, developed by Google’s Machine Intelligence research organization. Our team integrated the latest NVIDIA libraries, CUDA 9 and cuDNN 7, to enable mixed-precision training with NVIDIA Tensor Cores, which accelerate FP16 functionality on the latest NVIDIA Volta GPU, providing reduced training times with similar accuracy.
TensorFlow is a software library for numerical computation using data flow graphs, developed by Google’s Machine Intelligence research organization. Our team integrated the latest NVIDIA libraries, CUDA 9 and cuDNN 7, to enable mixed-precision training with NVIDIA Tensor Cores, which accelerate FP16 functionality on the latest NVIDIA Volta GPU, providing reduced training times with similar accuracy.
More implementations details on these TensorFlow integration PRs:
- Support for CUDA 9.0
- Add cuDNN 7 support
- Update NCCL and Eigen sources for CUDA 9
- Add support for CUBLAS_TENSOR_OP_MATH in fp16 GEMM
- Add fp16 support to fused batchnorm op
- GetConvolve*Algorithms return tensor-op algos
We also made changes that allow models to use the float16 data type, which is optimized by NVIDIA Tensor Cores, in layers, such as batch normalization, that reduces computation time in following layers, such as for convolution and matrix multiply. The below code snippet demonstrates a simple mixed-precision model that uses these features:
dtype = tf.float16
c, h, w, k, r = 64, 224, 224, 128, 7
infeed = tf.placeholder(dtype, (None, c, h, w))
x = tf.layers.conv2d(infeed, k, r, use_bias=False,
data_format='channels_first', padding='SAME')
x = tf.contrib.layers.batch_norm(x, data_format='NCHW', fused=True)
x = tf.layers.max_pooling2d(x, 2, 2, data_format='channels_first')
x = tf.reshape(x, (-1, k * (h // 2) * (w // 2)))
x = tf.layers.dense(x, 256)
x = tf.cast(x, tf.float32)
x = tf.nn.softmax(x)
NVIDIA Caffe
 Caffe is a deep learning framework made with expression, speed, and modularity in mind. Caffe is developed by the Berkeley Vision and Learning Center (BVLC). To support the Caffe community, our team maintains an optimized and updated public branch of Caffe. We added support for LARC (Layer-wise Adaptive Rate Control), allowing better scaling with a larger batch size and more nodes while maintaining accuracy. Some of the original details on these techniques are available in this research paper: Large Batch Training of Convolutional Networks with Layer-wise Adaptive Rate Scaling. Our NVIDIA Caffe GitHub has more details on our implementation.
Caffe is a deep learning framework made with expression, speed, and modularity in mind. Caffe is developed by the Berkeley Vision and Learning Center (BVLC). To support the Caffe community, our team maintains an optimized and updated public branch of Caffe. We added support for LARC (Layer-wise Adaptive Rate Control), allowing better scaling with a larger batch size and more nodes while maintaining accuracy. Some of the original details on these techniques are available in this research paper: Large Batch Training of Convolutional Networks with Layer-wise Adaptive Rate Scaling. Our NVIDIA Caffe GitHub has more details on our implementation.
Below is an example available in the ResNet50 definition prototxt file showing the additional LARC parameters accepted by the solver.
larc: true larc_policy: "clip" larc_eta: 0.002
We introduced adaptive gradient scaling support, which allows better training performance through automatic tuning of the learning rates based on information from the loss function. More details are available in the following reference research paper: A Robust Adaptive Stochastic Gradient Method for Deep Learning. You can find more details on the implementation of adaptive gradient scaling on our NVCaffe GitHub page.
PyTorch
![]() PyTorch is a deep learning framework that puts Python first using dynamic neural networks and tensors with strong GPU acceleration. We introduced enhancements to support NVIDIA Tensor Cores (FP16), available on the latest NVIDIA Volta GPU, allowing faster training of models. Here is a list of our GitHub pull requests that enable Tensor Core support:
PyTorch is a deep learning framework that puts Python first using dynamic neural networks and tensors with strong GPU acceleration. We introduced enhancements to support NVIDIA Tensor Cores (FP16), available on the latest NVIDIA Volta GPU, allowing faster training of models. Here is a list of our GitHub pull requests that enable Tensor Core support:
- Accumulate in accType for reductions over dimensions
- Batch norm layer for pseudo-fp16 support
- Use pseudo-fp16 for convolutions
- Half fixes for ATen
- Enable half communication for distributed
- Temporary fix for Issue, Cuda9 updates
- Fp16 fixes for CUDA 9
Here is an example of how to use this functionality for ImageNet training, by adding one simple flag –fp16:
python main.py -a alexnet --lr 0.01 --fp16 [imagenet-folder with train and val folders]
Below is an example of one of the many functions added for Tensor Core support from fp16util.py, which helps perform the conversion of ImageNet to FP16 while keeping batch norm layers in FP32 precision and maintaining training accuracy:
def BN_convert_float(module):
if isinstance(module, torch.nn.modules.batchnorm._BatchNorm):
module.float()
for child in module.children():
BN_convert_float(child)
return module
def network_to_half(network):
return nn.Sequential(tofp16(), BN_convert_float(network.half()))
Cognitive Toolkit
 The Microsoft Cognitive Toolkit —previously known as CNTK— is a unified deep-learning toolkit from Microsoft Research that makes it easy to train and combine popular model types across multiple GPUs and servers.
The Microsoft Cognitive Toolkit —previously known as CNTK— is a unified deep-learning toolkit from Microsoft Research that makes it easy to train and combine popular model types across multiple GPUs and servers.
Our team helped add support for NVIDIA Tensor Cores (Mixed-precision training with FP16) available on the latest NVIDIA Volta GPU, allowing reduced training times with similar accuracy. More details with master branch merge of CUDA 9, cuDNN 7 and Tensor Cores support on GitHub, as well as collaborating forked branch updates. Below is relevant code from an example to enable FP16 and casting input/loss:
graph_input = C.cast(input_var, dtype=np.float16)
graph_label = C.cast(label_var, dtype=np.float16)
with C.default_options(dtype=np.float16):
z = create_imagenet_model_bottleneck(graph_input, [2, 3, 5, 2], num_classes, stride1x1, stride3x3)
ce = cross_entropy_with_softmax(z, graph_label)
ce = C.cast(ce, dtype=np.float32)
Also, we introduced support for dilated convolutions, allowing faster training with fewer parameters through exponentially increasing the receptive field while keeping parameter growth linear. This feature is helpful in scenarios with higher resolution training images and where additional context can benefit text analysis. See this pull request for more details: Adding dilated convolution support
Theano
 Theano is a framework with a math expression compiler that efficiently defines, optimizes, and evaluates mathematical expressions involving multi-dimensional arrays. We worked closely with the Theano team to add FP16 mixed-precision training to Theano, as well as a caching mechanism to improve utilization of mixed-precision training.
Theano is a framework with a math expression compiler that efficiently defines, optimizes, and evaluates mathematical expressions involving multi-dimensional arrays. We worked closely with the Theano team to add FP16 mixed-precision training to Theano, as well as a caching mechanism to improve utilization of mixed-precision training.
For more details on our mixed-precision training contributions to Theano, see our GitHub pull request adding CUDA 9 and cuDNN 7.
Our addition of a caching mechanism to Theano’s “dnn.time_on_shape_change” and “dnn.time_once” config options, minimizes the expense of using them while improving the usage by trigging runtime benchmarking for cudnnFindConvolutionForwardAlgorithm and cudnnFindConvolutionBackwardFilterAlgorithm, which are necessary to select the best algos for mixed-precision training to fully utilize Volta’s Tensor Cores. For more details on the contribution to Theano, see our PR about the caching mechanism.
Here’s an example of how simple we’ve made it for a user to enable FP16 mixed-mode training and benchmarking cuDNN options in the .theanorc configuration file:
[global] floatX=float16 [dnn] enabled=True conv.algo_fwd=time_on_shape_change conv.algo_bwd_filter=time_once conv.algo_bwd_data=time_on_shape_change
Explore and Experiment
In summary, 2017 was a very busy year with significant contributions, such as Tensor Core support for Volta GPUs and performance improvements, to the open-source deep learning framework community. We worked across the popular deep learning frameworks to ensure optimal performance on NVIDIA GPUs.
All of our mentioned performance improvements, new features, and optimizations are packaged into docker containers that we update monthly with new enhancements and provide at no-cost via the NGC container registry (NVIDIA GPU Cloud). Due to the fast pace of updates in the deep learning community, we’re constantly improving our containers to ensure they provide you with all the latest updates for features and performance, including the open-source framework updates mentioned as well as the latest NVIDIA deep learning libraries, such as cuDNN and cuBLAS. Each month, through a rigorous testing process we ensure top performance and publish updated deep learning framework containers. As a user of deep learning frameworks, you can quickly explore and experiment with our NVIDIA optimized deep learning framework containers locally on your Pascal or Volta-based TITAN GPUs or on AWS through our NGC AMI. We’d love to hear your feedback the respective deep learning framework forums on DevTalk.
Let us know in the comments if there are other contributions you think were important for 2017 and what you learned through your explorations!
Author
Joey Conway is a product manager at NVIDIA focusing on Deep Learning Frameworks. Prior to joining NVIDIA, Joey worked as a product manager at Cisco, creating a next generation software analytics tool for improved troubleshooting of complex networking challenges. Joey holds an M.B.A from Massachusetts Institute of Technology Sloan School of Management and B.S. in Information Systems from Brigham Young University-Idaho.









