NVIDIA announced breakthroughs today in language understanding that give developers the opportunity to more naturally develop conversational AI applications using BERT and real-time inference tools, such as TensorRT to dramatically speed up their AI speech applications.
In today’s announcement, researchers and developers from NVIDIA set records in both training and inference of BERT, one of the most popular AI language models.
Training was performed in just 53 minutes on an NVIDIA DGX SuperPOD, using 1,472 V100 SXM3-32GB GPUs and 10 Mellanox Infiniband adapters per node, running PyTorch with Automatic Mixed Precision to accelerate throughput, using the training recipe in this paper.
Inference on BERT was performed in 2 milliseconds, 17x faster than CPU-only platforms, by running the model on NVIDIA T4 GPUs, using an open sourced model on GitHub and available from Google Cloud Platform’s AI Hub.
This level of performance makes it practical for developers to use state-of-the-art language understanding models in large-scale production applications. This will enable them to deploy their work and make it available to hundreds of millions of users worldwide.
Today’s announcement is key for conversational AI services such as chatbots, intelligent personal assistants, and search engines that need to operate with human-level comprehension.
Some of the early adopters of NVIDIA’s solution include Microsoft and some of the world’s most innovative startups.
“Large language models are revolutionizing AI for natural language,” said Bryan Catanzaro, vice president of Applied Deep Learning Research at NVIDIA. “They are helping us solve exceptionally difficult language problems, bringing us closer to the goal of truly conversational AI. NVIDIA’s groundbreaking work accelerating these models allows organizations to create new, state-of-the-art services that can assist and delight their customers in ways never before imagined.”
Highlights from Today’s Announcement
- Fastest training: Running the large version of one of the world’s most advanced AI language models — Bidirectional Encoder Representations from Transformers (BERT) — an NVIDIA DGX SuperPOD using 92 NVIDIA DGX-2H systems running 1,472 NVIDIA V100 GPUs slashed the typical training time for BERT-Large from several days to just 53 minutes. Additionally, NVIDIA trained BERT-Large on just one NVIDIA DGX-2 system in 2.8 days – demonstrating NVIDIA GPUs’ scalability for conversational AI.
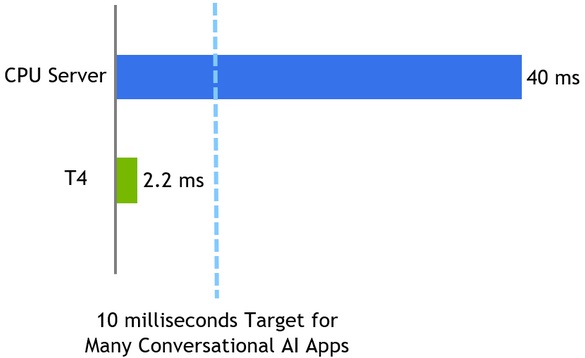
- Fastest inference: Using NVIDIA T4 GPUs running NVIDIA TensorRT, NVIDIA performed inference on the BERT-Base SQuAD dataset in only 2.2 milliseconds – well under the 10-millisecond latency threshold for many conversational AI applications, and a sharp improvement from over 40 milliseconds measured with highly optimized CPU code.
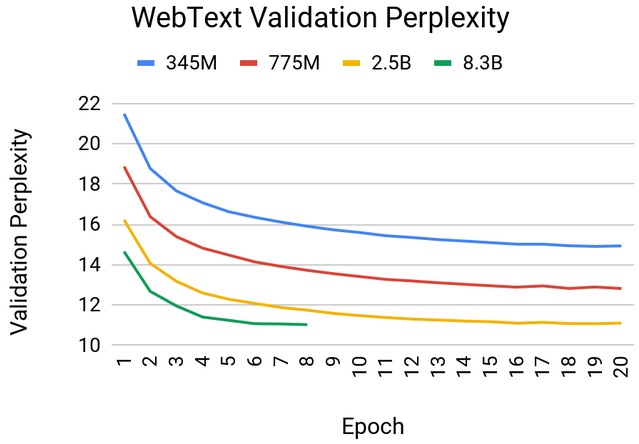
- Largest model: With a focus on developers’ ever-increasing need for larger models, NVIDIA Research built and trained the world’s largest language model based on Transformers, the technology building block used for BERT and a growing number of other natural language AI models. NVIDIA’s custom model, with 8.3 billion parameters, is 24 times the size of BERT-Large.
NVIDIA has made the software optimizations used to accomplish these breakthroughs in conversational AI available to developers:
- NVIDIA GitHub BERT training code with PyTorch *
- NGC model scripts and check-points for TensorFlow
- TensorRT optimized BERT Sample on GitHub and Developer Blog
- Faster Transformer: C++ API, TensorRT plugin, and TensorFlow OP
- MXNet Gluon-NLP with AMP support for BERT (training and inference)
- TensorRT optimized BERT Jupyter notebook on AI Hub
- Megatron-LM: PyTorch code for training massive Transformer models
*NVIDIA’s implementation of BERT is an optimized version of the popular Hugging Face repo