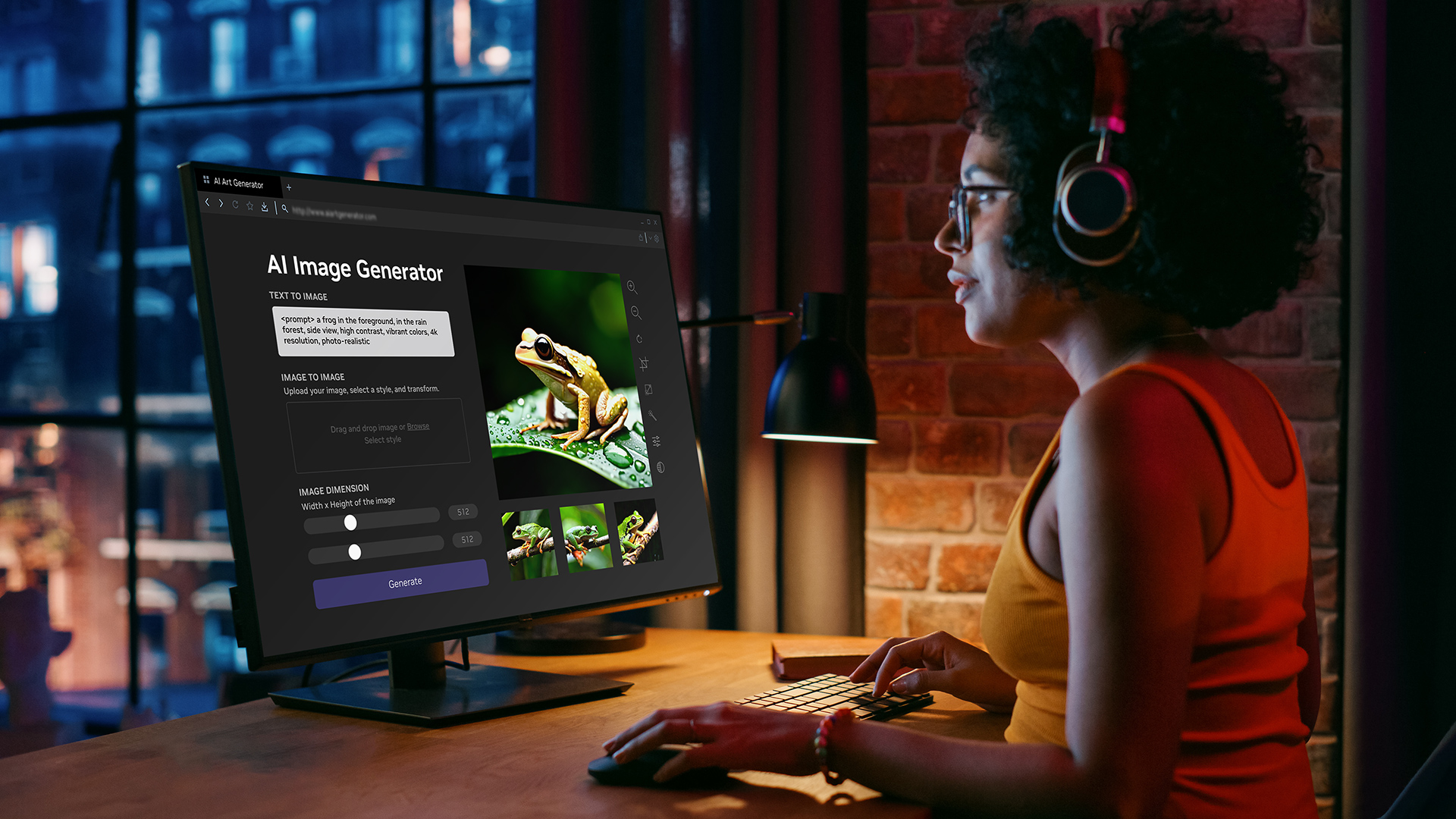
To continue to build robots that can safely and effectively collaborate with humans in warehouses and the home, NVIDIA researchers in the Seattle AI Robotics Research Lab developed a human-to-robot handover method in which the robot meets the human halfway.
The system, a proof of concept, results in more fluent handovers compared to previous approaches, and it has the potential to help warehouse robots and even kitchen assistants better interact with their human counterparts.
At the crux of the problem addressed here is the need to develop a perception system that can accurately identify a hand and objects in a variety of poses. Often, the hand and object are occluded by each other, and the human could be focused on another task while trying to pass the object to the robot. To solve the problem, the team broke the approach into several phases.
First, the team defined a set of grasps that describe the way the object is grasped by the human hand for the task of handover.
“If the hand is grasping a block, then the hand pose can be categorized as on-open-palm, pinch-bottom, pinchtop, pinch-side, or lifting,” the researchers explained in their paper, Human Grasp Classification for Reactive Human-to-Robot Handovers. “If the hand is not holding anything, it could be either waiting for the robot to handover an object or just doing nothing specific.”
Then, they trained a deep neural network to predict the human grasp categories on the point cloud. This was done by creating a dataset composed of eight subjects with various hand shapes and hand poses, using a Microsoft Azure Kinect RGBD camera.
“Specifically, we show an example image of a hand grasp to the subject, and record the subject performing similar poses from twenty to sixty seconds,” the researchers said. “The whole sequence of images [is] therefore labeled as the corresponding human grasp category. During the recording, the subject can move his/her body and hand to different positions to diversify the camera viewpoints. We record both left and right hands for each subject. In total, our dataset consists of 151,551 images.”

In the next phase, they adjusted the orientation of the robot’s grasp according to the human grasps.
This is done by training a human grasp classification network using the PointNet++ architecture due to its efficiency and success on many robotics applications such as markerless teleoperation system and grasps generation.
“Given a point cloud cropped around the hand, the network classifies it into one of the defined grasp categories, which would be used for further robot grasp planning,” the researchers said.

In this step, the team gives the robot canonical grasp directions which reduces the chance for the robot to grab the humans hand. This also makes the robot’s motion and trajectory as natural as possible.
The system was trained using one NVIDIA TITAN X GPU with CUDA 10.2 and the PyTorch framework. The testing was done with one NVIDIA RTX 2080 Ti GPU.
In sum, “the system consistently improved grasp success rate and reduced the total execution time and the trial duration compared with the two baseline methods, which proves the efficacy and reliability of our method,” the researchers said.

In future testing, the researchers plan to teach the system on additional grasp types to augment their dataset.