AI models that interpret and interact with the physical world rely on large image datasets, annotated so the neural network can learn exactly where one object ends and another begins.
But most models rely on crowdsourced datasets that are imperfect for the job — because an AI learning from a messy dataset doesn’t know that there’s a gap between the labeled boundaries it’s provided with and the real ground truth.
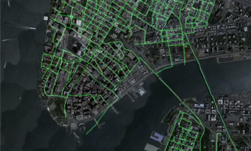
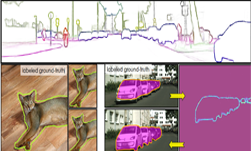
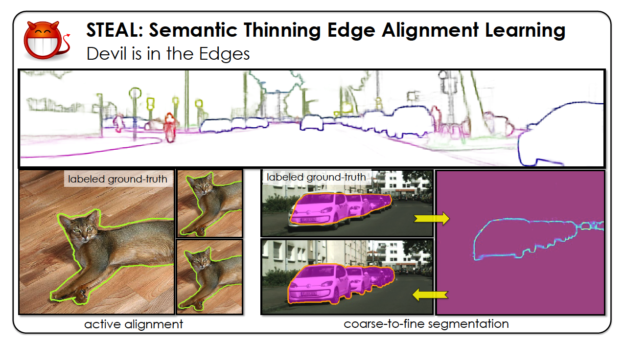
STEAL, a new algorithm developed by NVIDIA Research and being presented this week as an oral session at the annual CVPR conference, automatically refines the boundaries of objects in training datasets, making them more exact. This framework is a building block that could be plugged into neural networks to better train them on visual data with noisy annotations — boosting the performance of the AI models when they’re deployed.
Using an NVIDIA DGX Station, powered by four NVIDIA V100 GPUs, with the cuDNN-accelerated PyTorch deep learning framework, the NVIDIA researchers trained their algorithm on data from the Cityscapes dataset, a popular open-source dataset of urban street scenes.
Once trained, the team saw an improvement of four percent, when compared to the state-of-the-art model.
“If your deep learning method never sees accurately annotated boundaries, then it’s very hard for it to make accurate predictions at test time,” said Sanja Fidler, director of AI research at NVIDIA’s Toronto office.
Researchers can use STEAL, publicly available on GitHub, to refine their existing noisy datasets. But this work could also be used in annotation tools to collect new datasets faster.
“If researchers can annotate coarse blobs and use STEAL to have their models refine the boundaries, they could speed up annotation significantly,” Fidler said. “We can not only refine existing datasets, but also collect new datasets in a way that’s more efficient.”
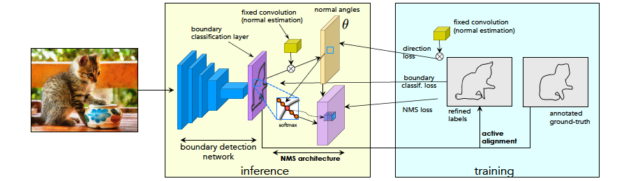
STEAL can be plugged into existing boundary detection models to better align human-annotated outlines with the true boundaries between objects.