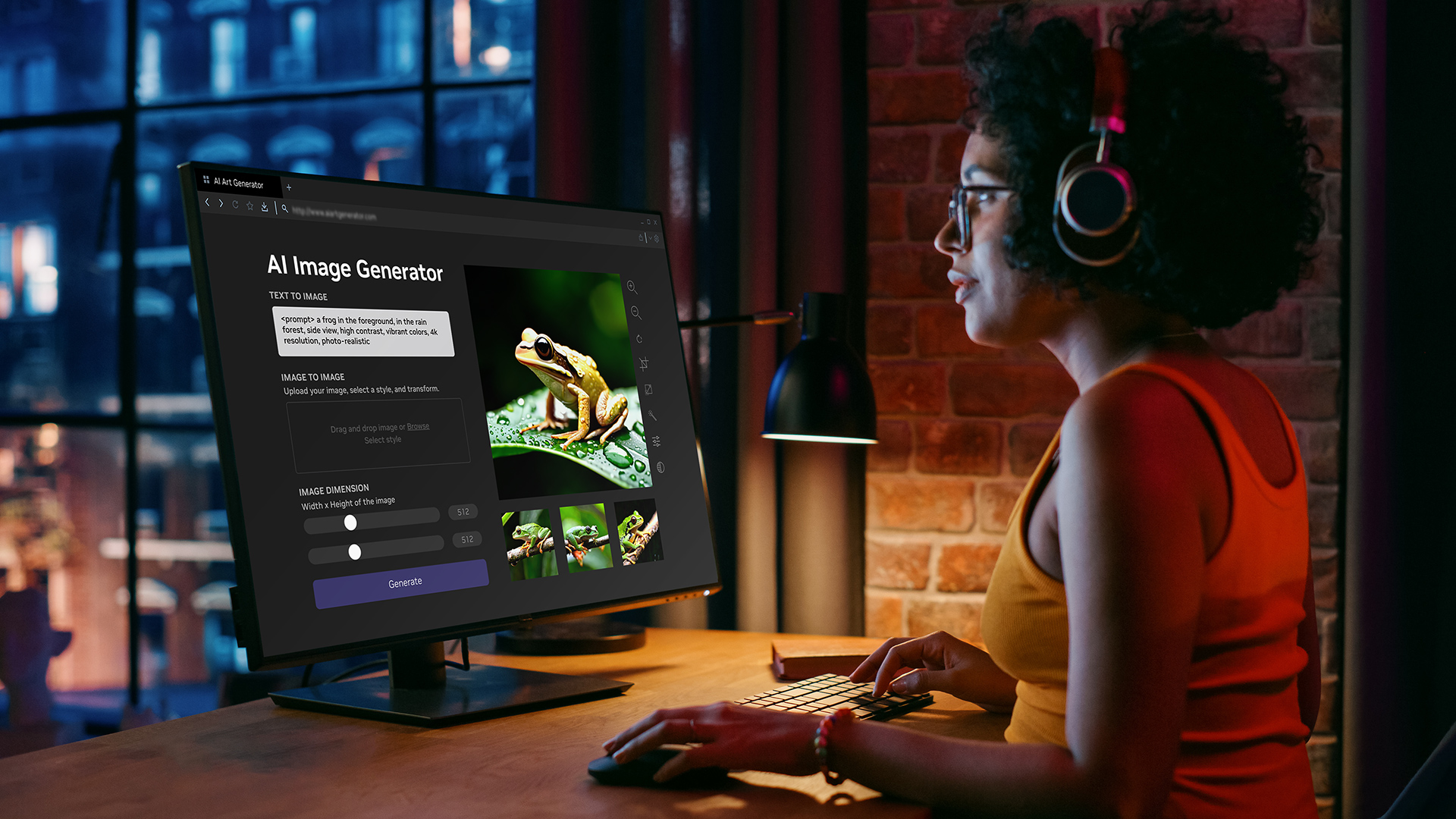
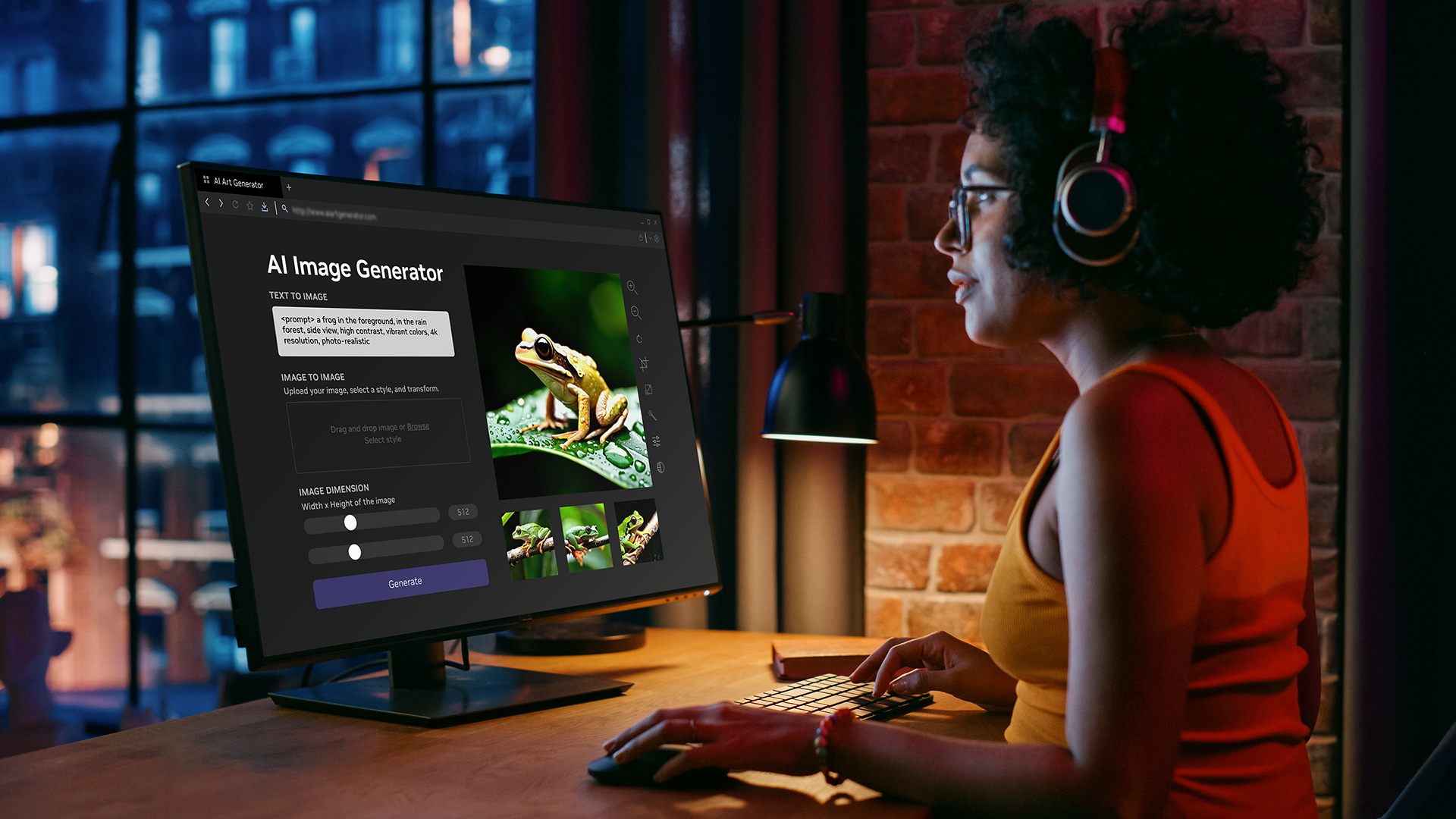
NVIDIA Researchers will present seven accepted papers and posted at the annual conference on Neural Information Processing Systems, Sun Dec 8th through Sat the 14th, 2019 at the Vancouver Convention Center.
Papers & Posters
Improved Precision and Recall Metric for Assessing Generative Models
Tuomas Kynkäänniemi · Tero Karras · Samuli Laine · Jaakko Lehtinen · Timo Aila
Tue Dec 10th 10:45 AM — 12:45 PM @ East Exhibition Hall B + C #128
The ability to automatically estimate the quality and coverage of the samples produced by a generative model is a vital requirement for driving algorithm research. We present an evaluation metric that can separately and reliably measure both of these aspects in image generation tasks by forming explicit, non-parametric representations of the manifolds of real and generated data. We demonstrate the effectiveness of our metric in StyleGAN and BigGAN by providing several illustrative examples where existing metrics yield uninformative or contradictory results. Furthermore, we analyze multiple design variants of StyleGAN to better understand the relationships between the model architecture, training methods, and the properties of the resulting sample distribution. In the process, we identify new variants that improve the state-of-the-art. We also perform the first principled analysis of truncation methods and identify an improved method. Finally, we extend our metric to estimate the perceptual quality of individual samples, and use this to study latent space interpolations.
High-Quality Self-Supervised Deep Image Denoising
Samuli Laine · Tero Karras · Jaakko Lehtinen · Timo Aila
Wed Dec 11th 10:45 AM — 12:45 PM @ East Exhibition Hall B + C #58
We describe a novel method for training high-quality image denoising models based on unorganized collections of corrupted images. The training does not need access to clean reference images, or explicit pairs of corrupted images, and can thus be applied in situations where such data is unacceptably expensive or impossible to acquire. We build on a recent technique that removes the need for reference data by employing networks with a “blind spot” in the receptive field, and significantly improve two key aspects: image quality and training efficiency. Our result quality is on par with state-of-the-art neural network denoisers in the case of i.i.d. additive Gaussian noise, and not far behind with Poisson and impulse noise. We also successfully handle cases where parameters of the noise model are variable and/or unknown in both training and evaluation data.
Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer
Wenzheng Chen · Huan Ling · Jun Gao · Edward Smith · Jaakko Lehtinen · Alec Jacobson · Sanja Fidler
Thu Dec 12th 05:00 — 07:00 PM @ East Exhibition Hall B + C #92
Many machine learning models operate on images, but ignore the fact that images are 2D projections formed by 3D geometry interacting with light, in a process called rendering. Enabling ML models to understand image formation might be key for generalization. However, due to an essential rasterization step involving discrete assignment operations, rendering pipelines are non-differentiable and thus largely inaccessible to gradient-based ML techniques. In this paper, we present DIB-Render, a novel rendering framework through which gradients can be analytically computed. Key to our approach is to view rasterization as a weighted interpolation, allowing image gradients to back-propagate through various standard vertex shaders within a single framework. Our approach supports optimizing over vertex positions, colors, normals, light directions and texture coordinates, and allows us to incorporate various well-known lighting models from graphics. We showcase our approach in two ML applications: single-image 3D object prediction, and 3D textured object generation, both trained using exclusively 2D supervision.
Joint-task Self-supervised Learning for Temporal Correspondence
Xueting Li · Sifei Liu · Shalini De Mello · Xiaolong Wang · Jan Kautz · Ming-Hsuan Yang
Wed Dec 11th 10:45 AM — 12:45 PM @ East Exhibition Hall B + C #65
This paper proposes to learn reliable dense correspondence from videos in a self-supervised manner. Our learning process integrates two highly related tasks: tracking large image regions and establishing fine-grained pixel-level associations between consecutive video frames. We exploit the synergy between both tasks through a shared inter-frame affinity matrix, which simultaneously models transitions between video frames at both the region- and pixel-levels. While region-level localization helps reduce ambiguities in fine-grained matching by narrowing down search regions; fine-grained matching provides bottom-up features to facilitate region-level localization. Our method outperforms the state-of-the-art self-supervised methods on a variety of visual correspondence tasks, including video-object and part-segmentation propagation, keypoint tracking, and object tracking. Our self-supervised method even surpasses the fully-supervised affinity feature representation obtained from a ResNet-18 pre-trained on the ImageNet.
Dancing to Music
Hsin-Ying Lee · Xiaodong Yang · Ming-Yu Liu · Ting-Chun Wang · Yu-Ding Lu · Ming-Hsuan Yang · Jan Kautz
Tue Dec 10th 10:45 AM — 12:45 PM @ East Exhibition Hall B + C #122
Dancing to music is an instinctive move by humans. Learning to model the music-to-dance generation process is, however, a challenging problem. It requires significant efforts to measure the correlation between music and dance as one needs to simultaneously consider multiple aspects, such as style and beat of both music and dance. Additionally, dance is inherently multimodal and various following movements of a pose at any moment are equally likely. In this paper, we propose a synthesis-by-analysis learning framework to generate dance from music. In the top-down analysis phase, we decompose a dance into a series of basic dance units, through which the model learns how to move. In the bottom-up synthesis phase, the model learns how to compose a dance by combining multiple basic dancing movements seamlessly according to input music. Experimental qualitative and quantitative results demonstrate that the proposed method can synthesize realistic, diverse, style-consistent, and beat-matching dances from music.
Few-shot Video-to-Video Synthesis
Ting-Chun Wang · Ming-Yu Liu · Andrew Tao · Guilin Liu · Bryan Catanzaro · Jan Kautz
Wed Dec 11th 05:00 — 07:00 PM @ East Exhibition Hall B + C #79
Video-to-video synthesis (vid2vid) aims at converting an input semantic video, such as videos of human poses or segmentation masks, to an output photorealistic video. While the state-of-the-art of vid2vid has advanced significantly, existing approaches share two major limitations. First, they are data-hungry. Numerous images of a target human subject or a scene are required for training. Second, a learned model has limited generalization capability. A pose-to-human vid2vid model can only synthesize poses of the single person in the training set. It does not generalize to other humans that are not in the training set. To address the limitations, we propose a few-shot vid2vid framework, which learns to synthesize videos of previously unseen subjects or scenes by leveraging few example images of the target at test time. Our model achieves this few-shot generalization capability via a novel network weight generation module utilizing an attention mechanism. We conduct extensive experimental validations with comparisons to strong baselines using several large-scale video datasets including human-dancing videos, talking-head videos, and street-scene videos. The experimental results verify the effectiveness of the proposed framework in addressing the two limitations of existing vid2vid approaches.
Exact Gaussian Processes on a Million Data Points
Ke Alexander Wang · Geoff Pleiss · Jacob Gardner · Stephen Tyree · Kilian Weinberger · Andrew Gordon Wilson
Wed Dec 11th 05:00 — 07:00 PM @ East Exhibition Hall B + C #169
Gaussian processes (GPs) are flexible non-parametric models, with a capacity that grows with the available data. However, computational constraints with standard inference procedures have limited exact GPs to problems with fewer than about ten thousand training points, necessitating approximations for larger datasets. In this paper, we develop a scalable approach for exact GPs that leverages multi-GPU parallelization and methods like linear conjugate gradients, accessing the kernel matrix only through matrix multiplication. By partitioning and distributing kernel matrix multiplies, we demonstrate that an exact GP can be trained on over a million points, a task previously thought to be impossible with current computing hardware. Moreover, our approach is generally applicable, without constraints to grid data or specific kernel classes. Enabled by this scalability, we perform the first-ever comparison of exact GPs against scalable GP approximations on datasets with 104 − 106 data points, showing dramatic performance improvements.
The NVIDIA Research team consists of more than 200 scientists around the globe, focusing on areas including AI, computer vision, self-driving cars, robotics and graphics.