NVIDIA Researchers will present 20 accepted papers and posters, eleven of them orals, at the annual Computer Vision and Pattern Recognition (CVPR) conference, June 16 – 20, in Long Beach, California.
Orals
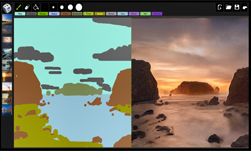
Semantic Image Synthesis With Spatially-Adaptive Normalization
Taesung Park, Ming-Yu Liu, Ting-Chun Wang, Jun-Yan Zhu
Tuesday, June 18, 2019 , 1330 – 1520 Oral 1.2B
We propose spatially-adaptive normalization, a simple but effective layer for synthesizing photorealistic images given an input semantic layout. Previous methods directly feed the semantic layout as input to the deep network, which is then processed through stacks of convolution, normalization, and nonlinearity layers. We show that this is suboptimal as the normalization layers tend to “wash away” semantic information. To address the issue, we propose using the input layout for modulating the activations in normalization layers through a spatially-adaptive, learned transformation. Experiments on several challenging datasets demonstrate the advantage of the proposed method over existing approaches, regarding both visual fidelity and alignment with input layouts. Finally, our model allows user control over both semantic and style as synthesizing images. Code will be available at this https URL.
STEP: Spatio-Temporal Progressive Learning for Video Action Detection
Xitong Yang, Xiaodong Yang, Ming-Yu Liu, Fanyi Xiao, Larry Davis, Jan Kautz
Tuesday, June 18, 2019 , 0900 – 1015 Oral 1.1C
In this paper, we propose Spatio-TEmporal Progressive (STEP) action detector—a progressive learning framework for spatio-temporal action detection in videos. Starting from a handful of coarse-scale proposal cuboids, our approach progressively refines the proposals towards actions over a few steps. In this way, high-quality proposals (i.e., adhere to action movements) can be gradually obtained at later steps by leveraging the regression outputs from previous steps. At each step, we adaptively extend the proposals in time to incorporate more related temporal context. Compared to the prior work that performs action detection in one run, our progressive learning framework is able to naturally handle the spatial displacement within action tubes and therefore provides a more effective way for spatio-temporal modeling. We extensively evaluate our approach on UCF101 and AVA, and demonstrate superior detection results. Remarkably, we achieve mAP of 75.0% and 18.6% on the two datasets with 3 progressive steps and using respectively only 11 and 34 initial proposals.
Efficient Video Classification Using Fewer Frames
Shweta Bhardwaj, Mukundhan Srinivasan, Mitesh M. Khapra
Tuesday, June 18, 2019 , 0900 – 1015 Oral 1.1C
Recently, there has been a lot of interest in building compact models for video classification which have a small memory footprint (<1 GB). While these models are compact, they typically operate by repeated application of a small weight matrix to all the frames in a video. E.g. recurrent neural network based methods compute a hidden state for every frame of the video using a recurrent weight matrix. Similarly, cluster-and-aggregate based methods such as NetVLAD, have a learnable clustering matrix which is used to assign soft-clusters to every frame in the video. Since these models look at every frame in the video, the number of floating point operations (FLOPs) is still large even though the memory footprint is small. We focus on building compute-efficient video classification models which process fewer frames and hence have less number of FLOPs. Similar to memory efficient models, we use the idea of distillation albeit in a different setting. Specifically, in our case, a compute-heavy teacher which looks at all the frames in the video is used to train a compute-efficient student which looks at only a small fraction of frames in the video. This is in contrast to a typical memory efficient Teacher-Student setting, wherein both the teacher and the student look at all the frames in the video but the student has fewer parameters. Our work thus complements the research on memory efficient video classification. We do an extensive evaluation with three types of models for video classification, viz.(i) recurrent models (ii) cluster-and-aggregate models and (iii) memory-efficient cluster-and-aggregate models and show that in each of these cases, a see-it-all teacher can be used to train a compute efficient see-very-little student. We show that the proposed student network can reduce the inference time by 30% and the number of FLOPs by approximately 90% with a negligible drop in the performance.
Joint Discriminative and Generative Learning for Person Re-identification
Zhedong Zheng, Xiaodong Yang, Zhiding Yu, Liang Zheng, Yi Yang, Jan Kautz
Tuesday, June 18, 2019 , 1330 – 1520 Oral 1.2A
Person re-identification (re-id) remains challenging due to significant intra-class variations across different cameras. Recently, there has been a growing interest in using generative models to augment training data and enhance the invariance to input changes. The generative pipelines in existing methods, however, stay relatively separate from the discriminative re-id learning stages. Accordingly, re-id models are often trained in a straightforward manner on the generated data. In this paper, we seek to improve learned re-id embeddings by better leveraging the generated data. To this end, we propose a joint learning framework that couples re-id learning and data generation end-to-end. Our model involves a generative module that separately encodes each person into an appearance code and a structure code, and a discriminative module that shares the appearance encoder with the generative module. By switching the appearance or structure codes, the generative module is able to generate high-quality cross-id composed images, which are online fed back to the appearance encoder and used to improve the discriminative module. The proposed joint learning framework renders significant improvement over the baseline without using generated data, leading to the state-of-the-art performance on several benchmark datasets.
A Style-Based Generator Architecture for Generative Adversarial Networks
Tero Karras, Samuli Laine, Timo Aila
Wednesday, June 19, 2019 , 0830 – 1000 Oral 2.1A
We propose an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature. The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identity when trained on human faces) and stochastic variation in the generated images (e.g., freckles, hair), and it enables intuitive, scale-specific control of the synthesis. The new generator improves the state-of-the-art in terms of traditional distribution quality metrics, leads to demonstrably better interpolation properties, and also better disentangles the latent factors of variation. To quantify interpolation quality and disentanglement, we propose two new, automated methods that are applicable to any generator architecture. Finally, we introduce a new, highly varied and high-quality dataset of human faces.
PlaneRCNN: 3D Plane Detection and Reconstruction from a Single View
Chen Liu, Kihwan Kim, Jinwei Gu, Yasutaka Furukawa, Jan Kautz
Wednesday, June 19, 2019 , 0830 – 1000 Oral 2.1B
This paper proposes a deep neural architecture, PlaneRCNN, that detects and reconstructs piecewise planar surfaces from a single RGB image. PlaneRCNN employs a variant of Mask R-CNN to detect planes with their plane parameters and segmentation masks. PlaneRCNN then jointly refines all the segmentation masks with a novel loss enforcing the consistency with a nearby view during training. The paper also presents a new benchmark with more fine-grained plane segmentations in the ground-truth, in which, PlaneRCNN outperforms existing state-of-the-art methods with significant margins in the plane detection, segmentation, and reconstruction metrics. PlaneRCNN makes an important step towards robust plane extraction, which would have an immediate impact on a wide range of applications including Robotics, Augmented Reality, and Virtual Reality.
Barrage of Random Transforms for Adversarially Robust Defense
Edward Raff; Jared Sylvester; Steven Forsyth; Mark McLean
Wednesday, June 19, 2019 , 1330 – 1520 Oral 2.2A
Defenses against adversarial examples, when using the ImageNet dataset, are historically easy to defeat. The common understanding is that a combination of simple image transformations and other various defenses are insufficient to provide the necessary protection when the obfuscated gradient is taken into account. In this paper, we explore the idea of stochastically combining a large number of individually weak defenses into a single barrage of randomized transformations to build a strong defense against adversarial attacks. We show that, even after accounting for obfuscated gradients, the Barrage of Random Transforms (BaRT) is a resilient defense against even the most difficult attacks, such as PGD. BaRT achieves up to a 24⇥ improvement in accuracy compared to previous work, and has even extended effectiveness out to a previously untested maximum adversarial perturbation of ✏ = 32.
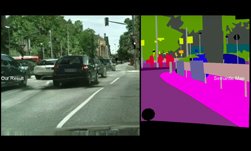
Improving Semantic Segmentation via Video Propagation and Label Relaxation
Yi Zhu, Karan Sapra, Fitsum A. Reda, Kevin J. Shih, Shawn Newsam, Andrew Tao, Bryan Catanzaro
Thursday, June 20, 2019 , 0830 – 1000 Oral 3.1C
Semantic segmentation requires large amounts of pixel-wise annotations to learn accurate models. In this paper, we present a video prediction-based methodology to scale up training sets by synthesizing new training samples in order to improve the accuracy of semantic segmentation networks. We exploit video prediction models’ ability to predict future frames in order to also predict future labels. A joint propagation strategy is also proposed to alleviate mis-alignments in synthesized samples. We demonstrate that training segmentation models on datasets augmented by the synthesized samples leads to significant improvements in accuracy. Furthermore, we introduce a novel boundary label relaxation technique that makes training robust to annotation noise and propagation artifacts along object boundaries. Our proposed methods achieve state-of-the-art mIoUs of 83.5% on Cityscapes and 82.9% on CamVid. Our single model, without model ensembles, achieves 72.8% mIoU on the KITTI semantic segmentation test set, which surpasses the winning entry of the ROB challenge 2018. Our code and videos can be found at this https URL.
Zheng Tang, Milind Naphade, Ming-Yu Liu, Xiaodong Yang, Stan Birchfield, Shuo Wang, Ratnesh Kumar, David Anastasiu, Jenq-Neng Hwang
Thursday, June 20, 2019 , 0830 – 1000 Oral 3.1B
Urban traffic optimization using traffic cameras as sensors is driving the need to advance state-of-the-art multi-target multi-camera (MTMC) tracking. This work introduces CityFlow, a city-scale traffic camera dataset consisting of more than 3 hours of synchronized HD videos from 40 cameras across 10 intersections, with the longest distance between two simultaneous cameras being 2.5 km. To the best of our knowledge, CityFlow is the largest-scale dataset in terms of spatial coverage and the number of cameras/videos in an urban environment. The dataset contains more than 200K annotated bounding boxes covering a wide range of scenes, viewing angles, vehicle models, and urban traffic flow conditions. Camera geometry and calibration information are provided to aid spatio-temporal analysis. In addition, a subset of the benchmark is made available for the task of image-based vehicle re-identification (ReID). We conducted an extensive experimental evaluation of baselines/state-of-the-art approaches in MTMC tracking, multi-target single-camera (MTSC) tracking, object detection, and image-based ReID on this dataset, analyzing the impact of different network architectures, loss functions, spatio-temporal models and their combinations on task effectiveness. An evaluation server is launched with the release of our benchmark at the 2019 AI City Challenge (this https URL) that allows researchers to compare the performance of their newest techniques. We expect this dataset to catalyze research in this field, propel the state-of-the-art forward, and lead to deployed traffic optimization(s) in the real world.
Neural RGB -> D Sensing: Depth and Uncertainty from a Video Camera
Chao Liu, Jinwei Gu, Kihwan Kim, Srinivasa Narasimhan, Jan Kautz
Thursday, June 20, 2019 , 1330 – 1520 Oral 3.2C
Depth sensing is crucial for 3D reconstruction and scene understanding. Active depth sensors provide dense metric measurements, but often suffer from limitations such as restricted operating ranges, low spatial resolution, sensor interference, and high power consumption. In this paper, we propose a deep learning (DL) method to estimate per-pixel depth and its uncertainty continuously from a monocular video stream, with the goal of effectively turning an RGB camera into an RGB-D camera. Unlike prior DL-based methods, we estimate a depth probability distribution for each pixel rather than a single depth value, leading to an estimate of a 3D depth probability volume for each input frame. These depth probability volumes are accumulated over time under a Bayesian filtering framework as more incoming frames are processed sequentially, which effectively reduces depth uncertainty and improves accuracy, robustness, and temporal stability. Compared to prior work, the proposed approach achieves more accurate and stable results, and generalizes better to new datasets. Experimental results also show the output of our approach can be directly fed into classical RGB-D based 3D scanning methods for 3D scene reconstruction.
Devil is in the Edges: Learning Semantic Boundaries from Noisy Annotations
David Acuna, Amlan Kar, Sanja Fidler
Thursday, June 20, 2019 , 1330 – 1520 Oral 3.2C
We tackle the problem of semantic boundary prediction, which aims to identify pixels that belong to object(class) boundaries. We notice that relevant datasets consist of a significant level of label noise, reflecting the fact that precise annotations are laborious to get and thus annotators trade-off quality with efficiency. We aim to learn sharp and precise semantic boundaries by explicitly reasoning about annotation noise during training. We propose a simple new layer and loss that can be used with existing learning-based boundary detectors. Our layer/loss enforces the detector to predict a maximum response along the normal direction at an edge, while also regularizing its direction. We further reason about true object boundaries during training using a level set formulation, which allows the network to learn from misaligned labels in an end-to-end fashion. Experiments show that we improve over the CASENet backbone network by more than 4% in terms of MF(ODS) and 18.61% in terms of AP, outperforming all current state-of-the-art methods including those that deal with alignment. Furthermore, we show that our learned network can be used to significantly improve coarse segmentation labels, lending itself as an efficient way to label new data.
Posters
SCOPS: Self-Supervised Co-Part Segmentation
Wei-Chih Hung, Varun Jampani, Sifei Liu, Pavlo Molchanov, Ming-Hsuan Yang, and Jan Kautz
Parts provide a good intermediate representation of objects that is robust with respect to the camera, pose and appearance variations. Existing works on part segmentation is dominated by supervised approaches that rely on large amounts of manual annotations and can not generalize to unseen object categories. We propose a self-supervised deep learning approach for part segmentation, where we devise several loss functions that aids in predicting part segments that are geometrically concentrated, robust to object variations and are also semantically consistent across different object instances. Extensive experiments on different types of image collections demonstrate that our approach can produce part segments that adhere to object boundaries and also more semantically consistent across object instances compared to existing self-supervised techniques.
Learning Linear Transformations for Fast Image and Video Style Transfer
Xueting Li, Sifei Liu, Jan Kautz, Ming-Hsuan Yang
Given a random pair of images, an arbitrary style transfer method extracts the feel from the reference image to synthesize an output based on the look of the other content image. Recent arbitrary style transfer methods transfer second order statistics from reference image onto content image via a multiplication between content image features and a transformation matrix, which is computed from features with a pre-determined algorithm. These algorithms either require computationally expensive operations, or fail to model the feature covariance and produce artifacts in synthesized images. Generalized from these methods, in this work, we derive the form of transformation matrix theoretically and present an arbitrary style transfer approach that learns the transformation matrix with a feed-forward network. Our algorithm is highly efficient yet allows a flexible combination of multi-level styles while preserving content affinity during style transfer process. We demonstrate the effectiveness of our approach on four tasks: artistic style transfer, video and photo-realistic style transfer as well as domain adaptation, including comparisons with the state-of-the-art methods.
Object Discovery in Videos as Foreground Motion Clustering
Christopher Xie, Yu Xiang, Zaid Harchaoui, Dieter Fox
We consider the problem of providing dense segmentation masks for object discovery in videos. We formulate the object discovery problem as foreground motion clustering, where the goal is to cluster foreground pixels in videos into different objects. We introduce a novel pixel-trajectory recurrent neural network that learns feature embeddings of foreground pixel trajectories linked across time. By clustering the pixel trajectories using the learned feature embeddings, our method establishes correspondences between foreground object masks across video frames. To demonstrate the effectiveness of our framework for object discovery, we conduct experiments on commonly used datasets for motion segmentation, where we achieve state-of-the-art performance.
Pixel-Adaptive Convolutional Neural Networks
Hang Su, Varun Jampani, Deqing Sun, Orazio Gallo, Erik Learned-Miller, Jan Kautz
Convolutions are the fundamental building block of CNNs. The fact that their weights are spatially shared is one of the main reasons for their widespread use, but it also is a major limitation, as it makes convolutions content agnostic. We propose a pixel-adaptive convolution (PAC) operation, a simple yet effective modification of standard convolutions, in which the filter weights are multiplied with a spatially-varying kernel that depends on learnable, local pixel features. PAC is a generalization of several popular filtering techniques and thus can be used for a wide range of use cases. Specifically, we demonstrate state-of-the-art performance when PAC is used for deep joint image upsampling. PAC also offers an effective alternative to fully-connected CRF (Full-CRF), called PAC-CRF, which performs competitively, while being considerably faster. In addition, we also demonstrate that PAC can be used as a drop-in replacement for convolution layers in pre-trained networks, resulting in consistent performance improvements.
Importance Estimation for Neural Network Pruning
Pavlo Molchanov, Arun Mallya, Stephen Tyree, Iuri Frosio, Jan Kautz
Structural pruning of neural network parameters reduces computation, energy, and memory transfer costs during inference. We propose a novel method that estimates the contribution of a neuron (filter) to the final loss and iteratively removes those with smaller scores. We describe two variations of our method using the first and secondorder Taylor expansions to approximate a filter’s contribution. Both methods scale consistently across any network layer without requiring per-layer sensitivity analysis and can be applied to any kind of layer, including skip connections. For modern networks trained on ImageNet, we measured experimentally a high (>93%) correlation between the contribution computed by our methods and a reliable estimate of the true importance. Pruning with the proposed methods leads to an improvement over state-ofthe-art in terms of accuracy, FLOPs, and parameter reduction. On ResNet-101, we achieve a 40% FLOPS reduction by removing 30% of the parameters, with a loss of 0.02% in the top-1 accuracy on ImageNet. Code is available at https://github.com/NVlabs/Taylor_pruning
Graphical Contrastive Losses for Scene Graph Parsing
Ji Zhang, Kevin J. Shih, Ahmed Elgammal, Andrew Tao, Bryan Catanzaro
Most scene graph parsers use a two-stage pipeline to detect visual relationships: the first stage detects entities, and the second predicts the predicate for each entity pair using a softmax distribution. We find that such pipelines, trained with only a cross entropy loss over predicate classes, suffer from two common errors. The first, Entity Instance Confusion, occurs when the model confuses multiple instances of the same type of entity (e.g. multiple cups). The second, Proximal Relationship Ambiguity, arises when multiple subject-predicate-object triplets appear in close proximity with the same predicate, and the model struggles to infer the correct subject-object pairings (e.g. mis-pairing musicians and their instruments). We propose a set of contrastive loss formulations that specifically target these types of errors within the scene graph parsing problem, collectively termed the Graphical Contrastive Losses. These losses explicitly force the model to disambiguate related and unrelated instances through margin constraints specific to each type of confusion. We further construct a relationship detector, called RelDN, using the aforementioned pipeline to demonstrate the efficacy of our proposed losses. Our model outperforms the winning method of the OpenImages Relationship Detection Challenge by 4.7\% (16.5\% relative) on the test set. We also show improved results over the best previous methods on the Visual Genome and Visual Relationship Detection datasets.
Anurag Ranjan, Varun Jampani, Lukas Balles, Kihwan Kim, Deqing Sun, Jonas Wulff, Michael J. Black
We address the unsupervised learning of several interconnected problems in low-level vision: single view depth prediction, camera motion estimation, optical flow, and segmentation of a video into the static scene and moving regions. Our key insight is that these four fundamental vision problems are coupled through geometric constraints. Consequently, learning to solve them together simplifies the problem because the solutions can reinforce each other. We go beyond previous work by exploiting geometry more explicitly and segmenting the scene into static and moving regions. To that end, we introduce Competitive Collaboration, a framework that facilitates the coordinated training of multiple specialized neural networks to solve complex problems. Competitive Collaboration works much like expectation-maximization, but with neural networks that act as both competitors to explain pixels that correspond to static or moving regions, and as collaborators through a moderator that assigns pixels to be either static or independently moving. Our novel method integrates all these problems in a common framework and simultaneously reasons about the segmentation of the scene into moving objects and the static background, the camera motion, depth of the static scene structure, and the optical flow of moving objects. Our model is trained without any supervision and achieves state-of-the-art performance among joint unsupervised methods on all sub-problems.
Kazuki Osawa, Yohei Tsuji, Yuichiro Ueno, Akira Naruse, Rio Yokota, Satoshi Matsuoka
Large-scale distributed training of deep neural networks suffer from the generalization gap caused by the increase in the effective mini-batch size. Previous approaches try to solve this problem by varying the learning rate and batch size over epochs and layers, or some ad hoc modification of the batch normalization. We propose an alternative approach using a second-order optimization method that shows similar generalization capability to first-order methods, but converges faster and can handle larger mini-batches. To test our method on a benchmark where highly optimized first-order methods are available as references, we train ResNet-50 on ImageNet. We converged to 75% Top-1 validation accuracy in 35 epochs for mini-batch sizes under 16,384, and achieved 75% even with a mini-batch size of 131,072, which took only 978 iterations.
Putting Humans in a Scene: Learning Affordance in 3D Indoor Environments
Xueting Li, Sifei Liu, Kihwan Kim, Xiaolong Wang, Ming-Hsuan Yang, Jan Kautz
Affordance modeling plays an important role in visual understanding. In this paper, we aim to predict affordances of 3D indoor scenes, specifically what human poses are afforded by a given indoor environment, such as sitting on a chair or standing on the floor. In order to predict valid affordances and learn possible 3D human poses in indoor scenes, we need to understand the semantic and geometric structure of a scene as well as its potential interactions with a human. To learn such a model, a large-scale dataset of 3D indoor affordances is required. In this work, we build a fully automatic 3D pose synthesizer that fuses semantic knowledge from a large number of 2D poses extracted from TV shows as well as 3D geometric knowledge from voxel representations of indoor scenes. With the data created by the synthesizer, we introduce a 3D pose generative model to predict semantically plausible and physically feasible human poses within a given scene (provided as a single RGB, RGB-D, or depth image). We demonstrate that our human affordance prediction method consistently outperforms existing state-of-the-art methods.
.