Twenty-five years ago NVIDIA transformed the computer graphics industry by building the first GPU, the modern day tool of the da Vincis and Einsteins of our time. Now, a new deep learning-based model developed by NVIDIA researchers aims to catapult the graphics industry into the AI chapter.
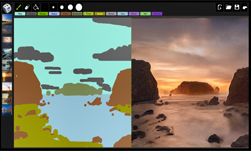
Using a conditional generative neural network as a starting point, the team trained a neural network to render new 3D environments, after being trained on existing videos.
This AI breakthrough will allow developers and artists to create new interactive 3D virtual worlds for automotive, gaming or virtual reality by training models on videos from the real world. This will lower the cost and time it takes to create virtual worlds.
The work was developed by a team of NVIDIA researchers led by Bryan Catanzaro, Vice President of Applied Deep Learning at NVIDIA.
“NVIDIA has been creating new ways to generate interactive graphics for 25 years – and this is the first time we can do this with a neural network,” Catanzaro said. “Neural networks – specifically – generative models are going to change the way graphics are created.”
“One of the main obstacles developers face when creating virtual worlds, whether for game development, telepresence, or other applications is that creating the content is expensive. This method allows artists and developers to create at a much lower cost, by using AI that learns from the real world,” Catanzaro said.
The research is currently on display at the NeurIPS conference in Montreal, Canada, a show attended by the world’s most prominent artificial intelligence researchers. The research team created a simple driving game for NeurIPS which allows attendees to interactively navigate an AI-generated environment.
The demo is made possible by NVIDIA Tensor Core GPUs and gives people a whole new way to experience interactive graphics.

“Before Tensor Cores, this demo would not have been possible,” Catanzaro said.
The network operates on high-level descriptions of a scene, for example: segmentation maps or edge maps, that describe where objects are and their general characteristics, such as whether a particular part of the image contains a car or a building, or where the edges of an object are. The network then fills in the details based on what it learned from real life videos.
The demo allows attendees to navigate a virtual urban environment that is being rendered by this neural network. The network was trained on videos of real-life urban environments. The conditional generative neural network learned to approximate the visual dynamics of the world such as lighting, and materials.
Since the output is synthetically generated, a scene can be easily edited to remove, modify, or add objects.
For training, the team used NVIDIA Tesla V100 GPUs on a DGX-1 with the cuDNN-accelerated PyTorch deep learning framework, and thousands of videos from the Cityscapes, and Apolloscapes datasets.
“The capability to model and recreate the dynamics of our visual world is essential to building intelligent agents,” the researchers stated in their paper. “Apart from purely scientific interests, learning to synthesize continuous visual experiences has a wide range of applications in computer vision, robotics, and computer graphics,” the researchers explained.
The paper and the interactive demo is being presented at NeurIPS in Montreal, Canada this week.
Although this research is early-stage, applications of this technology promise to make it much cheaper and easier to create virtual environments for many different domains.
Read more>
NVIDIA Invents AI Interactive Graphics
Dec 03, 2018
Discuss (0)

Related resources
- GTC session: Generative AI Theater: AI Decoded - Generative AI Spotlight Art With RTX PCs and Workstations
- GTC session: Insights from NVIDIA Research
- GTC session: Global Innovators: Scaling Innovation With NVIDIA AI
- SDK: Omniverse ACE
- SDK: NVIDIA Tokkio
- Webinar: Accelerate AI Model Inference at Scale for Financial Services