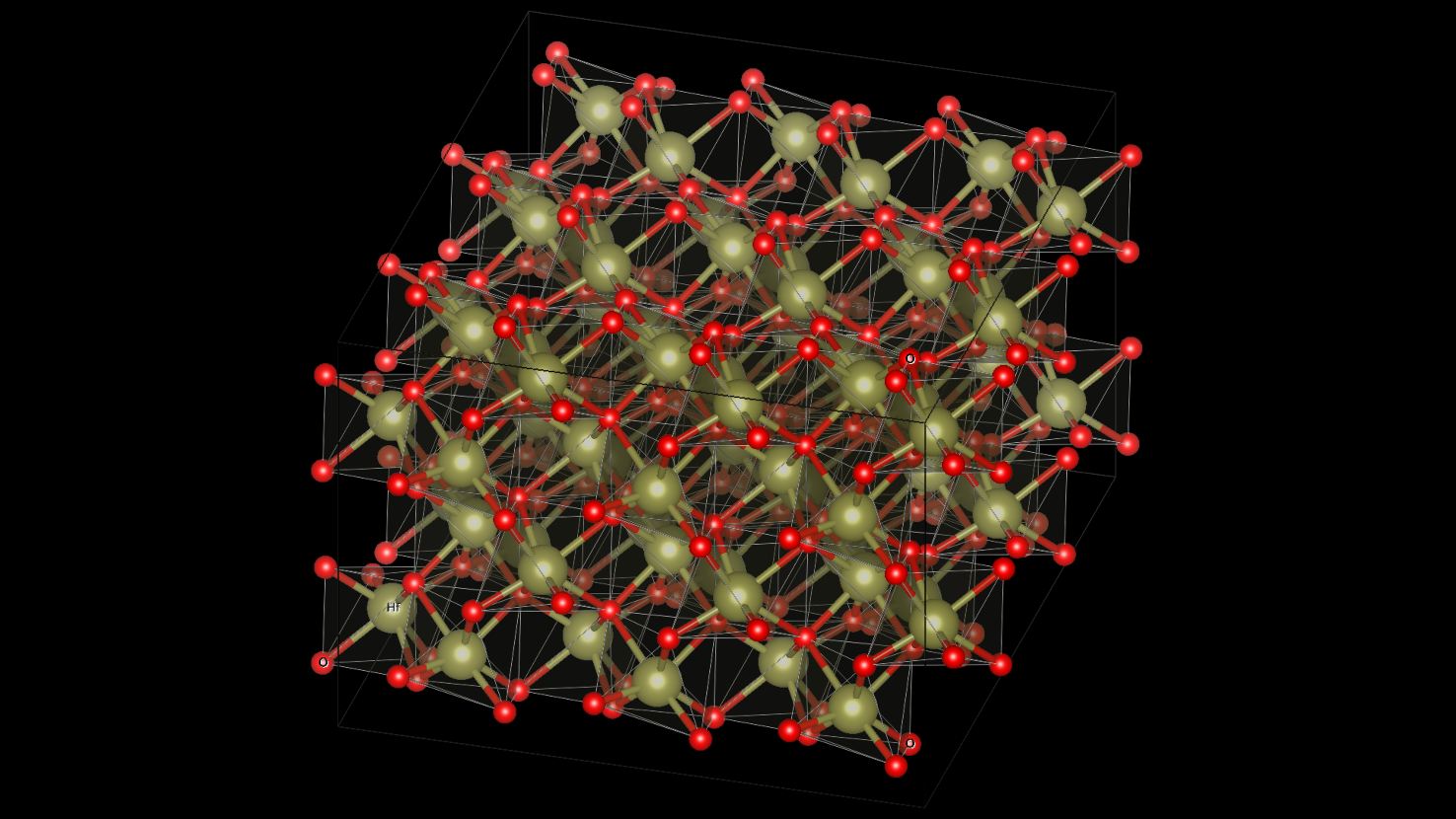
Developers of the world’s leading HPC application for atomic scale modelling, Vienna Ab initio Simulation Package (VASP), rolled out VASP 6.1.0 which ports new and expanded acceleration in NVIDIA GPUs through OpenACC.
VASP is one of the most widely used codes for electronic-structure calculations and first-principles molecular dynamics. Senior scientist and VASP lead developer Dr. Martijn Marsman presented GPU accelerated features including cubic-scaling RPA (ACFDT, GW), on-the-fly machine learning of force fields, electron-phonon coupling, and MPI+OpenMP parallelization. Additional features can be found on the product feature page.
The OpenACC port of VASP 6, released in late January 2020, will continue to improve through experimental feedback from NVIDIA GPU enabled HPC sites around the world with intensive developer support in conjunction with NVIDIA engineering teams.
The blocked-Davidson algorithm (including exact exchange) and RMM-DIIS for the real-space projection scheme were previously ported to CUDA C with good speed-ups on GPUs, but also with an increase in the maintenance workload because VASP is otherwise written entirely in Fortran.
The new approach using OpenACC directives combined with calling NVIDIA libraries allowed us to extend GPU acceleration to gamma-point-only calculations, the reciprocal projection scheme and to direct minimizers with higher productivity and increased maintainability of the code because we can focus on a unified code base for the CPU and GPU version of VASP. It also allowed us to offer first-day GPU acceleration for features newly introduced into VASP, including adaptively compressed exchange (ACE) and a double-buffering implementation for hybrid DFT calculations. The improved performance and the vastly decreased maintenance effort has led the VASP group to adopt OpenACC as the programming model for all future GPU porting of VASP.
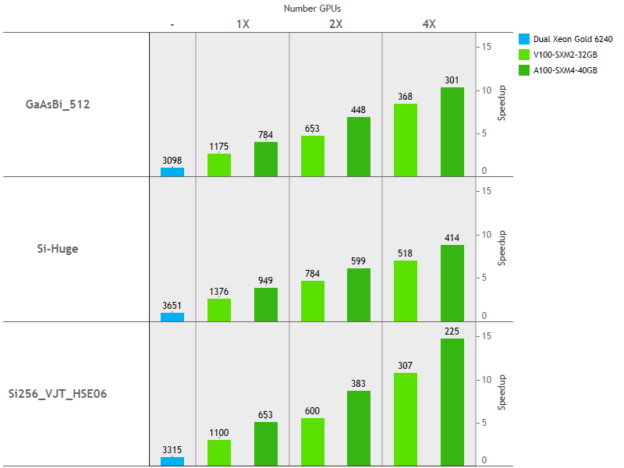
The new GPU version with OpenACC is about 2x faster than the previous implementation, delivers nearly 15x more performance compared to traditional CPU-only simulations, and additionally accelerates the following features now:
- Gamma-point simplifications
- Reciprocal space projectors
- Standard and Hybrid DFT levels of theory for direct minimizers (“Damped” and “All” algorithms)
- Adaptively Compressed Exchange that makes hybrid DFT with Davidson algorithm 3x faster
- Double-buffered Exact Exchange to overlap communication with computation to enable better scaling
VASP 6 also offers the following exciting features to the scientific community
- Electron-Phonon coupling
- On-the-fly machine-learned force fields
- Cubically scaling RPA (ACFDT, GW)
Scientists can run VASP 6 on any NVIDIA GPU. Stay informed on the latest performance guide to run VASP 6 on NVIDIA GPUs using the VASP GPU-ready guide. The strongest double-precision performance is available on NVIDIA V100 and NVIDIA A100, the latest GPU architecture. To learn more about NVIDIA A100 architecture see the NVIDIA Ampere architecture whitepaper