Today, the MLPerf consortium published its first results for the seven tests that currently comprise this new industry-standard benchmark for machine learning. For the six test categories where NVIDIA submitted results, we’re excited to tell you that NVIDIA platforms have finished with leading single-node and at-scale results for all six, a testament to our total platform approach to accelerating machine learning.
What is MLPerf, you ask? According to the consortium’s mission statement, “The MLPerf effort aims to build a common set of benchmarks that enables the machine learning (ML) field to measure system performance for both training and inference from mobile devices to cloud services.” NVIDIA has been a key member of the MLPerf consortium, actively working with other members to build, refine and evolve this first agreed-upon set of workloads so that platforms can be directly compared across a range of use cases.
As a nascent and rapidly-growing market, the machine learning space has lacked industry-standard benchmarks for evaluating platforms. While networks like ResNet-50 have often been used as a performance proxy for both training and inference, it remains a single CNN used primarily for image-based tasks. As such, it cannot by itself provide a complete performance picture of a machine learning platform. Machine learning includes many other use-cases such as speech, translation and recommendation systems among others.
Say Hello to MLPerf
One of MLPerf’s key design goals is workload diversity, and to that end, it covers image and natural language usages, as well as a recommender system and reinforcement learning for a total of seven tests. Today, these workloads test training only, with inference-focused workloads planned for a future version.
| Usage | Model | Data-Set |
| Image Classification | ResNet-50 v1.5 | ImageNet |
| Object Instance Segmentation | Mask R-CNN | COCO |
| Object Detection | Single-Shot Detector | COCO |
| Translation (recurrent) | GNMT | WMT English-German |
| Translation (non-recurrent) | Transformer | WMT English-German |
| Recommendation | NCF | MovieLens 20M |
| Reinforcement Learning | Mini-Go |
NVIDIA focused our initial efforts on the Closed division, which is intended to provide meaningful comparisons of ML training systems (a system consists of hardware and software). To achieve this goal, the Closed division requires that all submissions train the same neural network model architecture, using the same data preparation, as well as training procedure. This ensures all entries are as equivalent as possible from the application point of view, and that performance differences are due to software, hardware, or scale differences. Network models, data sets, and training procedures in the Closed division are chosen to represent computations common in the machine learning community today. The Open division, on the other hand, is not intended for system comparison, but to encourage innovation in network model architectures and other algorithmic aspects.
NVIDIA submitted results for six of the seven test categories, opting not to submit for the Reinforcement Learning test. This test is based on an implementation of the strategy game Go that was originally developed on servers using P100 GPUs. However, in its current form, it has a significant CPU component, and as a result can only offer limited scaling.
MLPerf scores are computed by first measuring time to train to the specified target accuracy, then normalizing to the time taken by an unoptimized implementation on a reference platform. The goal of normalization is to have similar magnitude of scores across different benchmarks, since benchmarks take different amounts of time to train. Both the time-to-train and MLPerf scores are published on the MLPerf web site, and so we present time to train in minutes. Here are the NVIDIA time to convergence results, both for single-node and at-scale implementations:
Single-Node Closed Division GPU performance:

At-Scale Closed Division GPU performance:

Several things initially jump out of these numbers: a single DGX-2 node can complete many of these workloads in under twenty minutes. And in the case of our at-scale submission, we’re completing these tasks in under seven minutes in all but one of the tests. GPUs delivered up to 5.3x faster results compared to the next fastest submissions. Given that in the early days of deep learning, training was measured in days and weeks, these completion times speak to the huge amounts of progress we’ve made in just the last few years. This chart illustrates how far we’ve come with training ResNet-50-type models:
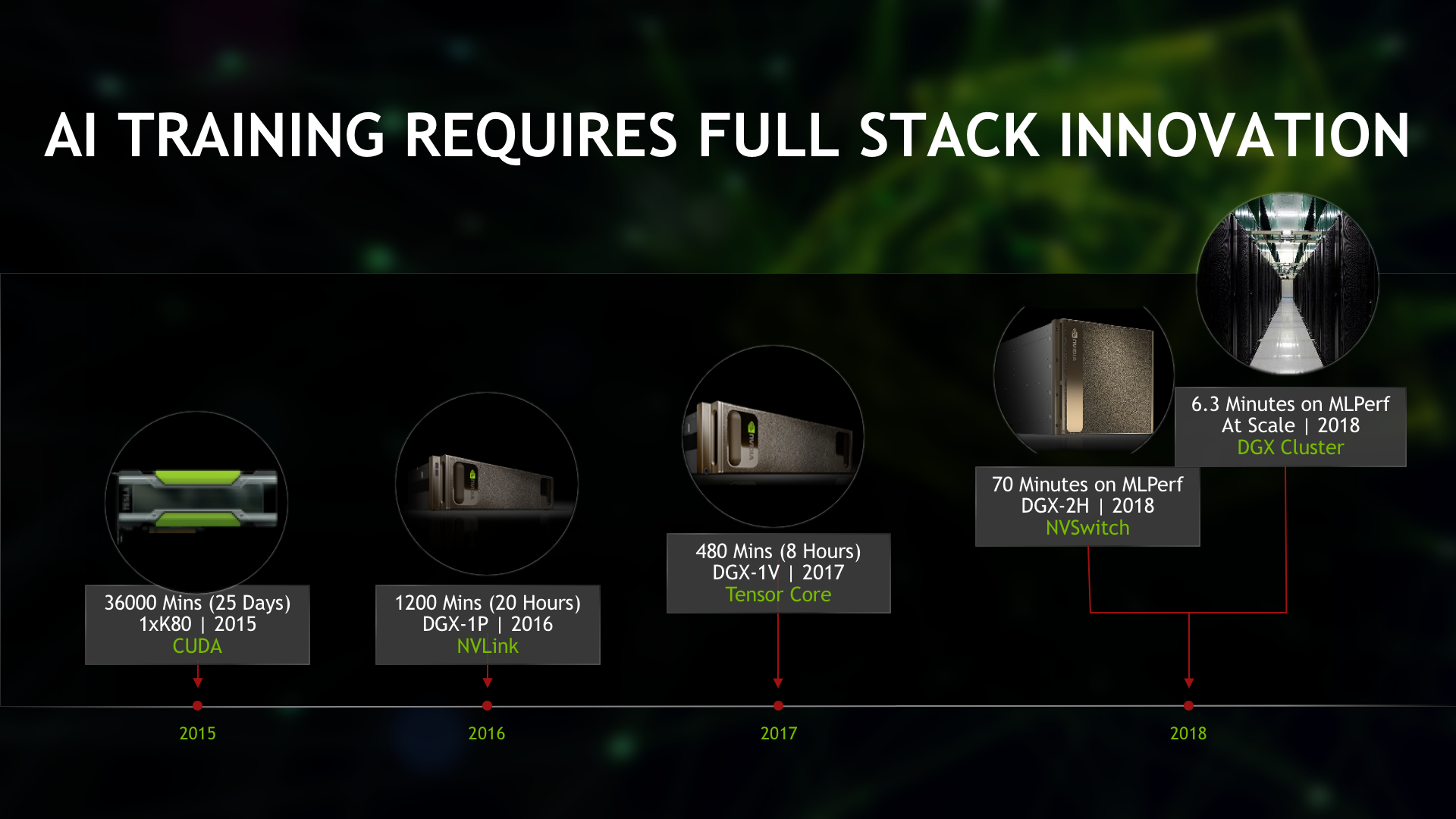
What becomes clear is that a series of platform innovations have enabled dramatic gains in performance over the last few years. These innovations include:
-
- NVLink Fabric Technology: introduced in the Pascal architecture, NVLink allows GPUs to communicate at 300GB/sec, nearly 10x faster than PCIe.
-
- Tensor Cores: introduced in the Volta architecture, Tensor Cores accelerate large matrix operations, which are at the heart of AI, and perform mixed-precision matrix multiply and accumulate calculations in a single operation.
- NVSwitch: the first on-node switch architecture to support 16 fully-connected GPUs in a single server node and drive simultaneous communication between all eight GPU pairs at 300 GB/s each. These 16 GPUs can be used as a single large-scale accelerator with 0.5 Terabytes of unified memory space and 2 petaFLOPS of deep learning compute power.
Full-Stack Optimization: The Right Approach
NVIDIA’s approach to accelerating deep learning involves our entire platform, and an ongoing stream of innovation with our hardware, software and ecosystem support. This approach has paid big dividends for the deep learning community, allowing developers to achieve great performance using any of the popular frameworks on any cloud service provider, or using their own GPU infrastructure. NVIDIA submissions to MLPerf used MXNet for the Image Classification workload (ResNet-50) and PyTorch for submissions covering Translation, Object Detection and Instance Segmentation, and Recommender workloads. Google’s TensorFlow team also demonstrated excellent results on ResNet-50 using NVIDIA V100 GPUs on the Google Cloud Platform.
The frameworks are all freely available in our NVIDIA GPU Cloud (NGC) container registry, and are updated on a monthly cadence with continual performance improvements. We published a blog describing the recent improvements to the NVIDIA deep learning software stack available in the November 18.11 container release. Here is a snapshot of those improvements:
MXNet
-
-
- Added Horovod for better performance when training across multiple nodes.
-
- Optimized performance for larger scale multi-node training with small batch sizes (<= 32)
- For addition details, refer to this blog at AWS that specifically outlines recent improvements to MXNet.
-
TensorFlow
-
- Updated XLA graph compiler with optimizations for operator fusion to save memory bandwidth, and optimizations for Tensor Core data layouts. This recent blog from Google goes into more specific details.
PyTorch
-
- Added new utilities in Apex with a fused implementation of the Adam optimizer to improve performance by reducing redundant GPU device memory passes, improved layer normalization performance for convolutional translation models, and improved DistributedDataParallel wrapper for multi-process and multi-node training.
cuDNN
-
- Various significant performance improvements for convolutions, especially at small batch sizes per GPU, and optimized persistent RNN algorithm for Tensor Cores.
DALI
-
- Accelerated various image pre-processing routines needed by object detection models, so they can run on the GPU instead of the CPU.
Conclusion
Here at NVIDIA, we’re very encouraged by this first set of published results, and are proud of the collaborative work done with the framework development teams in the AI community. MLPerf will serve as an instrument that allows AI platform makers to compare their offerings using an agreed-upon set of use-cases, and we will continue to work with the MLPerf consortium to iterate this benchmark as AI workloads evolve. The technologies that went into producing these results are now available to the AI developer community from our NGC container registry. Learn more about the specific optimizations in the TensorFlow, PyTorch and MXNet frameworks in our recent Developer Blog. The MLPerf benchmark models are available at www.mlperf.org, and can be run according to the README in each benchmark directory.
SINGLE-NODE:
[1] Image Classification result on MLPerf v0.5 Training Closed; result by NVIDIA on DGX-2H system (16 GPUs) employed ngc18.11_MXNet Framework with cuDNN 7.4 library. Retrieved from www.mlperf.org 12 December 2018, entry 0.5.20.1.
[2] Object Detection Heavy-Weight result on MLPerf v0.5 Training Closed; result by NVIDIA on DGX-2H system (16 GPUs) employed ngc18.11_PyTorch Framework with cuDNN 7.4 library. Retrieved from www.mlperf.org 12 December 2018, entry 0.5.21.3.
[3] Object Detection Light-Weight result on MLPerf v0.5 Training Closed; result by NVIDIA on DGX-2H system (16 GPUs) employed ngc18.11_PyTorch Framework with cuDNN 7.4 library. Retrieved from www.mlperf.org 12 December 2018, entry 0.5.21.2.
[4] Recurrent Translation result on MLPerf v0.5 Training Closed; result by NVIDIA on DGX-2H system (16 GPUs) employed ngc18.11_PyTorch Framework with cuDNN 7.4 library. Retrieved from www.mlperf.org 12 December 2018, entry 0.5.21.4.
[5] Non-Recurrent Translation result on MLPerf v0.5 Training Closed; result by NVIDIA on DGX-2H system (16 GPUs) employed ngc18.11_PyTorch Framework with cuDNN 7.4 library. Retrieved from www.mlperf.org 12 December 2018, entry 0.5.21.5.
[6] Recommendation result on MLPerf v0.5 Training Closed; result by NVIDIA on DGX-2H system (16 GPUs) employed ngc18.11_PyTorch Framework with cuDNN 7.4 library. Retrieved from www.mlperf.org 12 December 2018, entry 0.5.21.6.
AT-SCALE RESULTS:
[7] Image Classification result on MLPerf v0.5 Training Closed; result by NVIDIA on DGX cluster (640 GPUs) employed ngc18.11_MXNet Framework with cuDNN 7.4 library. Retrieved from www.mlperf.org 12 December 2018, entry 0.5.17.1.
[8] Object Detection Heavy-Weight result on MLPerf v0.5 Training Closed; result by NVIDIA on 4xDGX-2H systems (64 GPUs) employed ngc18.11_PyTorch Framework with cuDNN 7.4 library. Retrieved from www.mlperf.org 12 December 2018, entry 0.5.22.3.
[9] Object Detection Light-Weight result on MLPerf v0.5 Training Closed; result by NVIDIA on 8xDGX-2H systems (64 GPUs) employed ngc18.11_PyTorch Framework with cuDNN 7.4 library. Retrieved from www.mlperf.org 12 December 2018, entry 0.5.23.2.
[10] Recurrent Translation result on MLPerf v0.5 Training Closed; result by NVIDIA on 16xDGX-2H systems (256 GPUs) employed ngc18.11_PyTorch Framework with cuDNN 7.4 library. Retrieved from www.mlperf.org 12 December 2018, entry 0.5.24.4.
[11] Non-Recurrent Translation result on MLPerf v0.5 Training Closed; result by NVIDIA on 24xDGX-1 system (192 GPUs) employed ngc18.11_PyTorch Framework with cuDNN 7.4 library. Retrieved from www.mlperf.org 12 December 2018, entry 0.5.15.5