Inference is where AI-based applications really go to work. Object recognition, image classification, natural language processing, and recommendation engines are but a few of the growing number of applications made smarter by AI.
Recently, TensorRT 5, the latest version of NVIDIA’s inference optimizer and runtime, became available. This version brings new features including support for our newest accelerator, the NVIDIA T4 Cloud GPU, so it takes full advantage of T4’s new Turing Tensor Cores, which accelerate INT8 precision more than 2x faster than the previous generation low-power offering. Also new is TensorRT Inference Server, a containerized inference microservice that maximizes NVIDIA GPU utilization and seamlessly integrates into DevOps deployments with Docker and Kubernetes.
Any inference platform is ultimately measured on the performance and versatility it brings to the market, and NVIDIA V100 and T4 accelerators deliver on all fronts.
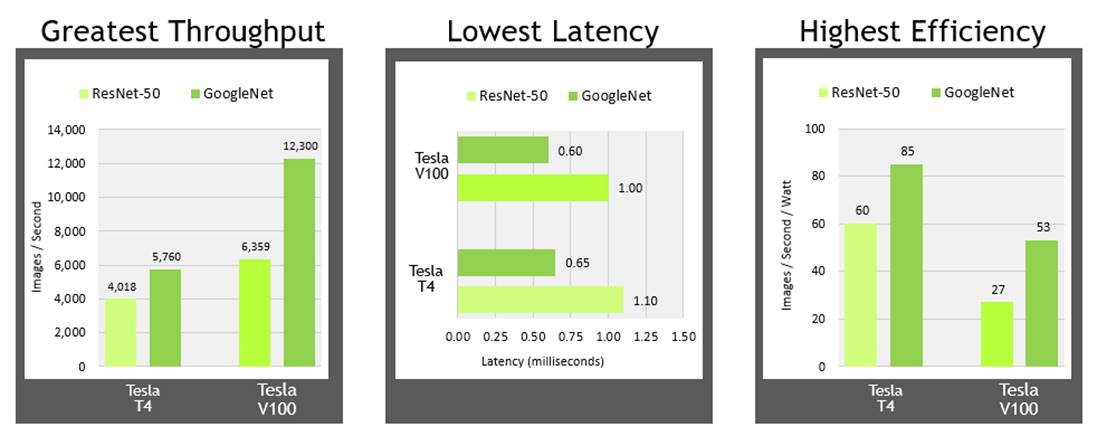
Throughput: Both NVIDIA T4 and V100 deliver levels of throughput that enable all kinds of trained networks to perform at their best, and even run multiple networks to run on a single GPU. The data shown here are for high batch throughput, typically run with a batch size of 128 where low latency isn’t necessarily a concern, since high-volume throughput is paramount.
Latency: For the growing numbers of AI-powered real-time services, low latency is a critical factor, and both NVIDIA V100 and T4 can deliver around 1ms latencies to make real-time services scale easily.
Efficiency: Another critical consideration to maximize data center productivity is delivering great performance in as small an energy footprint as possible. And while V100 offers higher overall throughput, T4 really shines on efficiency, hitting up to 85 images/sec/Watt.
Speed is Just the Beginning
We recently discussed a framework called PLASTER, which expresses the seven critical elements to inference performance.

NVIDIA data center platforms deliver on all seven of these factors, accelerating inference on all types of networks built using any of the deep learning frameworks. Today’s V100 and T4 both offer great performance, programmability and versatility, but each is designed for different data center infrastructure designs.
V100 is designed for scale-up deployments, where purpose-built servers will each be equipped with four to GPUs each to tackle heavy-duty workloads like AI training and HPC. They can also deliver massive inference performance, and be retasked to take on any of these workloads as needed.
For its part, T4 is purpose-built for scale-out server designs, where each server will likely have one to two GPUs each. T4’s low-profile PCIe form-factor and 70W power footprint mean it can be installed into existing server deployments, dramatically extending the service life of those servers with a significant performance kicker. This type of server deployment can ably handle inference – both high-batch and real-time — as well as video transcoding and even distributed training workloads.
Storm is Coming
As AI-powered services continue to grow both in number and sophistication, the clear trend they are driving is the need for accelerated inference. Relying on “after-hours” spare CPU cycles may have been adequate in the past, but as networks grow in size and complexity to power smarter AI-powered products and services, these trends are overwhelming the CPU-only practices of the past. The latest services are already employing state-of-the-art AI, and will be executing multiple inferences across different types of networks to service a single user request. For instance, asking your digital assistant for a recommendation can involve:
- Automatic Speech Recognition (to convert the request from speech to text)
- Natural Language Processing (to understand the question)
- A Recommender System (to answer the question being asked)
- Natural Language Processing (to convert the answer into conversational language)
- Speech Synthesis (to convert the text into a natural-sounding spoken answer)
That’s five different inference operations for just one request, all of which have to happen in well under one second. These trends underscore the need for accelerated inference to not only enable services like the example above, but accelerate their arrival to market. NVIDIA V100 and T4 GPUs have the performance and programmability to be the single platform to accelerate the increasingly diverse set of inference-driven services coming to market.
So whether it’s scale-up or scale-out, accelerating any kind of network built using any framework, NVIDIA V100 and T4 are more than ready to meet the challenge, delivering the high throughput, low latency and great efficiency needed to make these services and products a reality.