Today, NVIDIA posted the fastest results on new MLPerf benchmarks measuring the performance of AI inference workloads in data centers and at the edge. The new results come on the heels of the company’s equally strong results in the MLPerf benchmarks posted earlier this year.
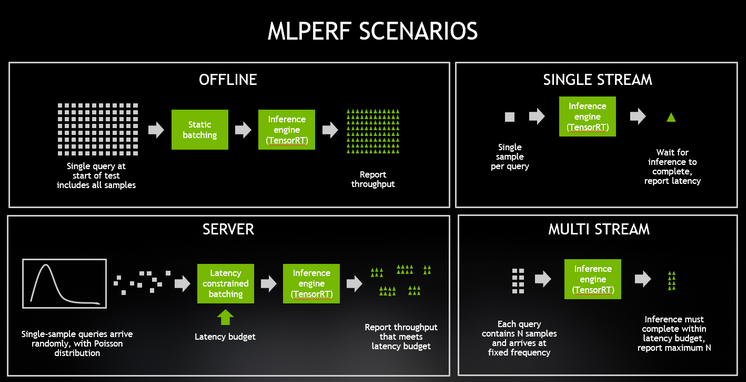
MLPerf’s five inference benchmarks — applied across a range of form factors and four inferencing scenarios — cover such established AI applications as image classification, object detection and translation.
Use cases and benchmarks are:
| Area | Task | Model | Dataset |
| Vision | Image classification | Resnet50-v1.5 | ImageNet (224×224) |
| Vision | Image classification | MobileNet-v1 | ImageNet (224×224) |
| Vision | Object detection | SSD-ResNet34 | COCO (1200×1200) |
| Vision | Object detection | SSD-MobileNet-v1 | COCO (300×300) |
| Language | Machine translation | GMNT | WMT16 |
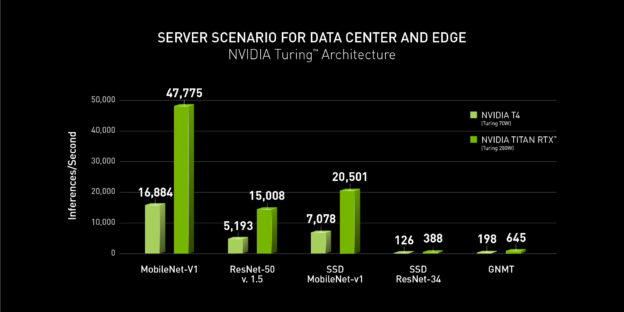
NVIDIA topped all five benchmarks for both data center-focused scenarios (server and offline), with Turing GPUs providing the highest performance per processor among commercially available entries. Xavier provided the highest performance among commercially available edge and mobile SoCs under both edge-focused scenarios (single-stream and multistream).
All of NVIDIA’s MLPerf results were achieved using NVIDIA TensorRT 6 high-performance deep learning inference software that optimizes and deploys AI applications easily in production from the data center to the edge. New TensorRT optimizations are also available as open source in the GitHub repository. See the full results and benchmark details in this developer blog.
In addition to being the only company that submitted on all five of MLPerf Inference v0.5’s benchmarks, NVIDIA also submitted in the Open Division an INT4 implementation of ResNet-50v1.5. This implementation delivered a 59% throughput increase with an accuracy loss of less than 1.1% In this blog, we’ll take you through a brief overview of our INT4 submission, which is derived from earlier research at NVIDIA to assess the performance and accuracy of INT4 inference on Turing. Learn more about INT4 Precision here.
Expanding its inference platform, NVIDIA today also introduced Jetson Xavier NX, the world’s smallest, most powerful AI supercomputer for robotic and embedded computing devices at the edge.
The Jetson Xavier NX module is pin-compatible with Jetson Nano and is based on a low-power version of NVIDIA’s Xavier SoC that led the recent MLPerf Inference 0.5 results among edge SoCs, providing increased performance for deploying demanding AI-based workloads at the edge that may be constrained by factors like size, weight, power, and cost. Learn more about the new system here, and see how captured the top spot in 4 out 5 categories.