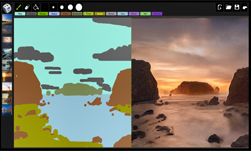
With just the beginning and end frames, this 3D convolutional neural network can fill in the gaps. The process, known as “inbetweening,” can generate intermediate frames between two given points. The technique is normally executed by training and running recurrent neural networks.
In this work, using NVIDIA V100 GPUs for training, Google AI researchers instead used a 3D CNN to generate meaningful and diverse in-between video sequences.
“Imagine if we could teach an intelligent system to automatically turn comic books into animation,” the Google researchers stated in their paper. “Being able to do so would undoubtedly revolutionize the animation industry.”
The proposed model put forth by the Google team consists of three components: a 2D-convolutional image encoder, a 3D-convolutional latent representation generator, and a video generator.
“Our key finding is that separating the generation of the latent representation from video decoding is of crucial importance to successfully address video inbetweening. Indeed, attempting to generate the final video directly from the encoded representations of the start and end frames tends to perform poorly,” the Google researchers stated. “To this end, we carefully design the latent representation generator to stochastically fuse the keyframe representations and progressively increase the temporal resolution of the generated video.”
Using NVIDIA V100 GPUs, and the cuDNN-accelerated TensorFlow deep learning framework with training and validation data from three well-known public datasets, including the BAIR robot pushing, KTH Action Database, and UCF101 Action Recognition Data Set, the team trained and validated their neural network to generate different sequences consistent with the given keyframes.

The results: each sample in the data set contained 16 frames in total, 14 of which the neural networks generated. The model ran over 100 times for each pair of keyframes. The entire procedure was repeated 10 times for each model variant.

“Despite having no recurrent components, our model produces good performance on most widely-used benchmark datasets. The key to success for this approach is a dedicated component that learns a latent video representation, decoupled from the final video decoding phase,”
The research was recently published on ArXiv.