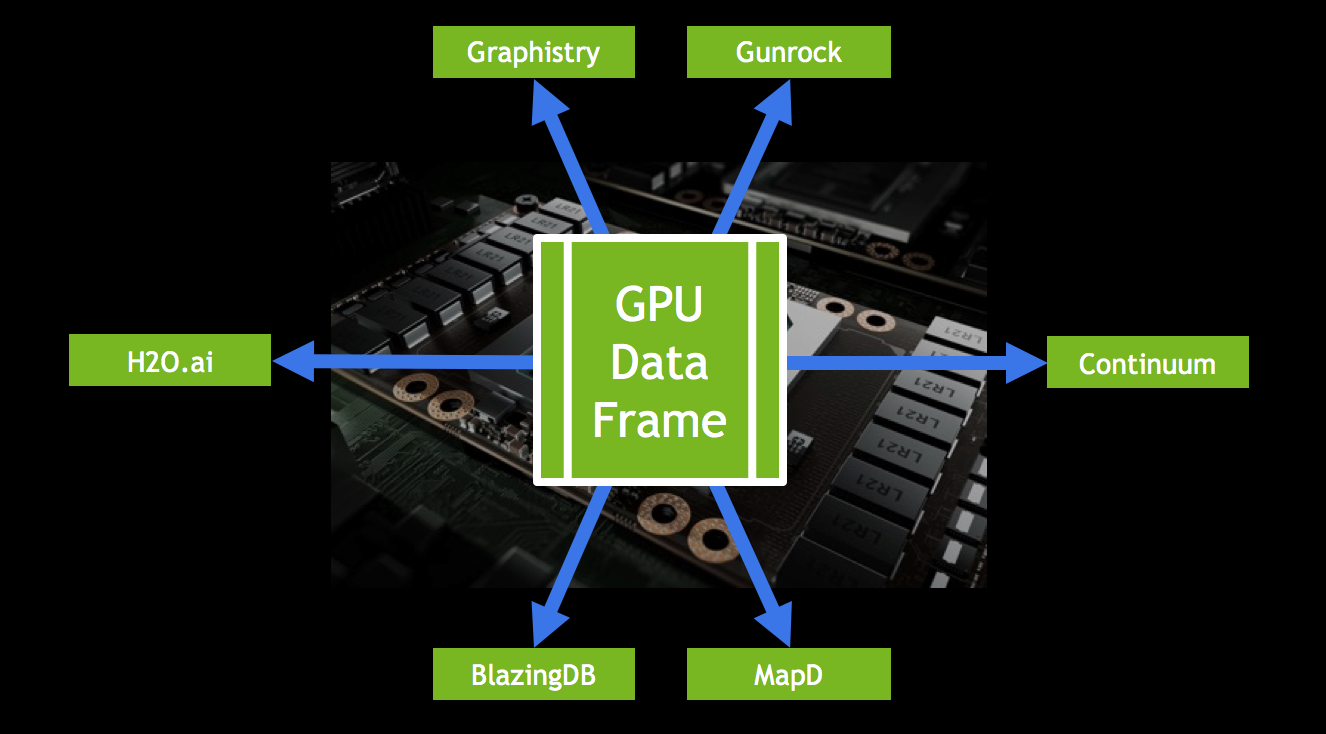
Continuum Analytics, H2O.ai, and MapD recently announced the formation of the GPU Open Analytics Initiative (GOAI) to create common data frameworks enabling developers and statistical researchers to accelerate data science on GPUs.
GOAI, also joined by BlazingDB, Graphistry and Gunrock from UC Davis, will foster the development of a data science ecosystem on GPUs by allowing resident applications to interchange data seamlessly and efficiently. Bringing standard analytics data formats to GPUs will allow data analytics to be even more efficient, and to take advantage of the high throughput of GPUs. NVIDIA believes this initiative is a key contributor to the continued growth of GPU computing in accelerated analytics.
GOAI helps streamline the data pipeline and allows developers to fully utilize the performance of GPUs. Most data scientists and engineers are familiar with traditional big data tools like Hadoop and Spark and languages like Java, SQL, Scala, Python, and R. In data science, Python, SQL, and R are the leading languages for data manipulation and exploration, with popular packages like Pandas and Data.Table. GOAI will provide access to GPU computing with data science tools commonly used in enterprises applications and Kaggle competitions.
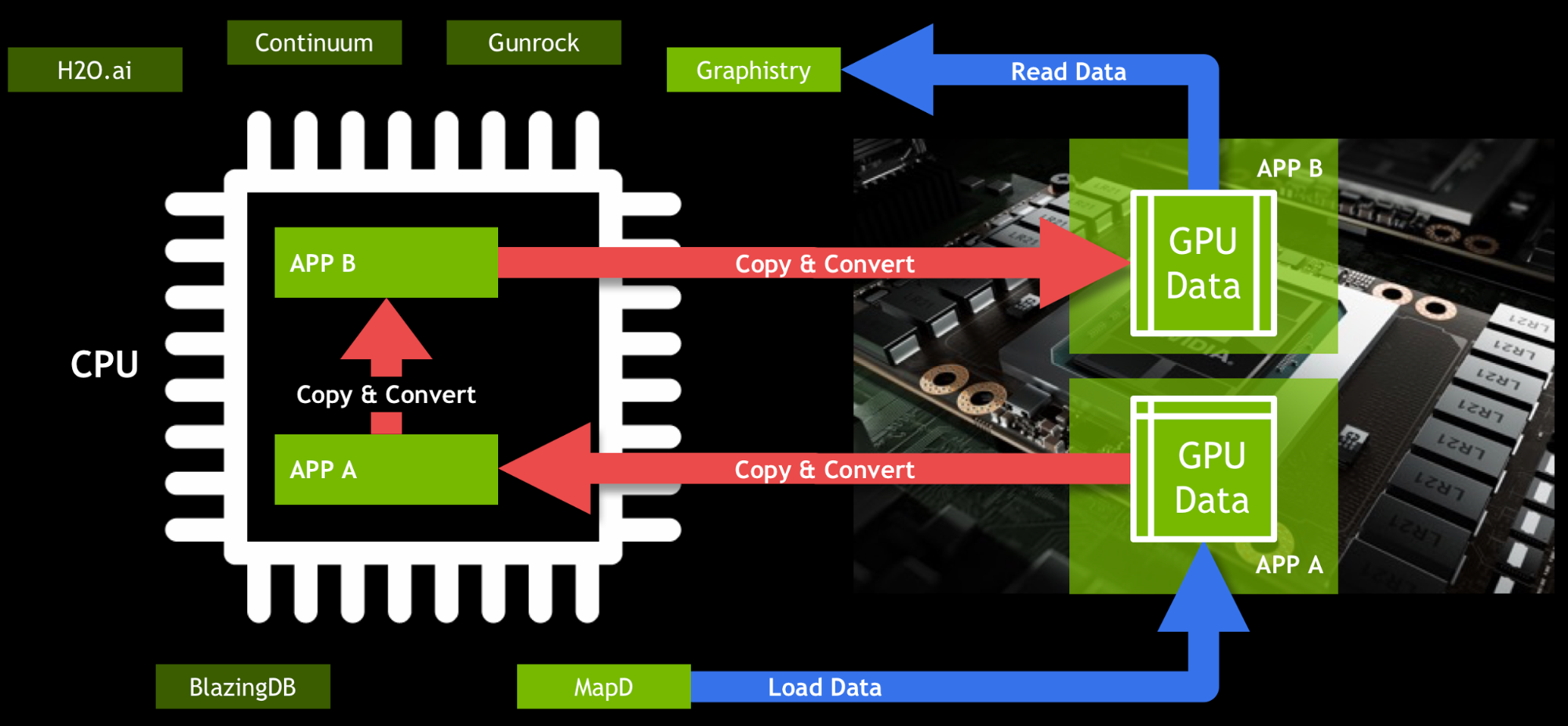
In a new post on the NVIDIA Parallel Forall blog, Joshua Patterson and Keith Kraus walk through the steps of using GOAI’s new GPU Data Frame API in Python to perform machine learning algorithms on data stored in a MapD GPU-accelerated database. The GPU Data Frame allows direct sharing of data on the GPU between data science applications. The python code in the notebook runs a Generalized Linear Model from H20.ai on US Census data stored in a MapD database, achieving over a 35x speedup comparing the 8 Tesla P100 GPUs of an NVIDIA DGX to a dual-Xeon CPU-only system.
Read more >
Related resources
- DLI course: Accelerating Data Engineering Pipelines
- GTC session: More Data, Faster: GPU Memory Management Best Practices in Python and C++
- GTC session: Toward Large-Scale Relational Database Analytics on GPUs
- GTC session: Generative AI Theater: A GPU-Accelerated Vector Database
- SDK: RAPIDS Accelerator for Spark
- SDK: GPUDirect Storage