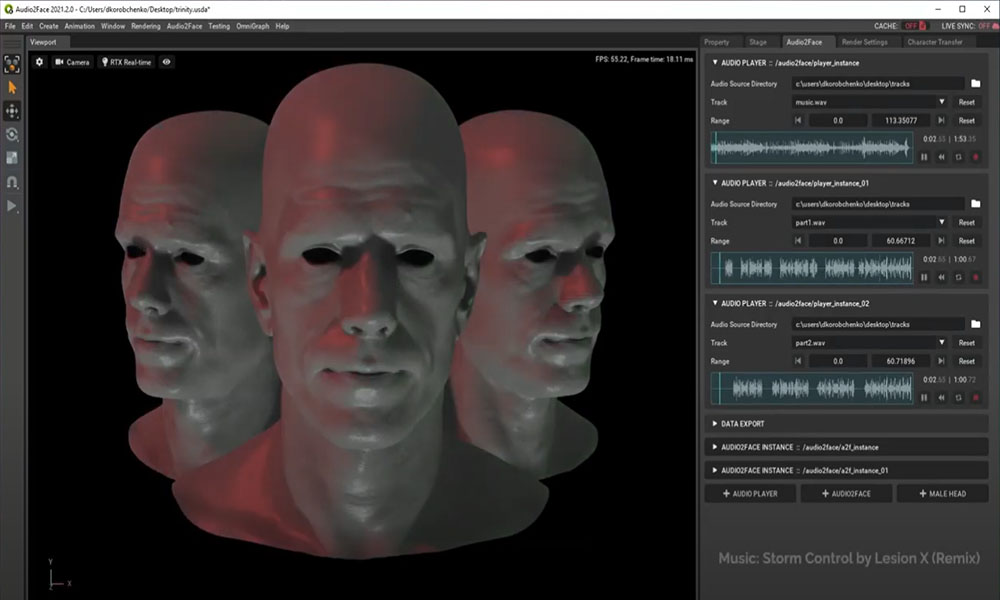
Researchers from NVIDIA and the independent game developer Remedy Entertainment developed an automated real-time deep learning technique to create 3D facial animations from audio with low latency.
Using a TITAN Xp GPU and the cuDNN-accelerated Theano deep learning framework, the researchers trained their neural network on nearly ten minutes of high-quality audio and expression data obtained from two human actors. They had the actors speak one to three pangrams (sentences that are designed to contain as many different phonemes as possible, in several different emotional tones to provide a good coverage of the range of expression), and in-character material (preliminary version of the script) which leverages the fact that an actor’s performance of a character is often heavily biased in terms of emotional and expressive range for various dramatic and narrative reasons.
As mentioned in their paper: “Our deep neural network learns a mapping from input waveforms to the 3D vertex coordinates of a face model, and simultaneously discovers a compact, latent code that disambiguates the variations in facial expression that cannot be explained by the audio alone. During inference, the latent code can be used as an intuitive control for the emotional state of the face puppet.
This study’s primary goal was to model the speaking style of a single actor, but the deep learning technique yields reasonable results even for speakers of different gender with different accents or languages. The technique can be used for in-game dialogue, low-cost localization, virtual reality avatars, and telepresence.
The team from NVIDIA Research and Remedy Entertainment will present their paper next week at SIGGRAPH in Los Angeles.
Learn more about how NVIDIA is bringing AI to the graphics industry at SIGGRAPH >
Related resources
- GTC session: One-Click Creation of Hyper-Realistic 3D Characters from AI-Powered Conversations and Designs
- GTC session: Behind the Scenes of Running a Conversational Character in a 3D Scene
- GTC session: Build a World of Interactive Avatars Based on NVIDIA Omniverse, AIGC, and LLM
- NGC Containers: MATLAB
- SDK: NVIDIA Tokkio
- Webinar: How Telcos Transform Customer Experiences with Conversational AI