Facebook published a paper today detailing how they are able to train nearly 1.3 million images in under an hour using 256 Tesla P100 GPUs that previously took days on a single system.
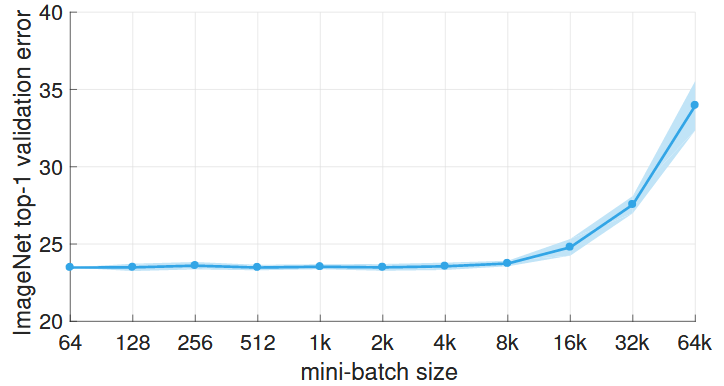
The team reduced the training time of a ResNet-50 deep learning model on ImageNet from 29 hours to one – which they did so by distributing training in larger minibatches across more GPUs. Previously, batches of 256 images were spread across eight Tesla P100 GPUs, but today’s work shows the same level of accuracy when training with large minibatch sizes up to 8,192 images distributed across 256 GPUs.
According to the paper, “to achieve this result, we adopt a linear scaling rule for adjusting learning rates as a function of minibatch size and develop a new warmup scheme that overcomes optimization challenges early in training.” They were able to achieve near-linear SGD scaling by using an optimized allreduce implementation. For the local reduction, they used NVIDIA Collective Communications Library (NCCL) that implements multi-GPU collective communication primitives that are performance optimized for NVIDIA GPUs.
Facebook used the open source deep learning framework Caffe2 and their Big Basin GPU server that has eight NVIDIA Tesla P100 GPU accelerators that are interconnected using NVIDIA NVLink.
Read more >
Related resources
- DLI course: Building a Brain in 10 Minutes
- DLI course: Deep Learning at Scale with Horovod
- GTC session: Scaling Generative AI Features to Millions of Users Thanks to Inference Pipeline Optimizations
- GTC session: Transforming 2D Imagery into 3D Geospatial Tiles With Neural Radiance Fields
- GTC session: AI for Learning Photorealistic 3D Digital Humans from In-the-Wild Data
- NGC Containers: MATLAB