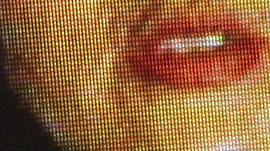
University of Washington researchers developed a deep learning-based system that converts audio files into realistic mouth shapes, which are then grafted onto and blended with the head of that person from another existing video.
“These type of results have never been shown before,” said Ira Kemelmacher-Shlizerman, an assistant professor at the UW’s Paul G. Allen School of Computer Science & Engineering and co-author of the research. “Realistic audio-to-video conversion has practical applications like improving video conferencing for meetings, as well as futuristic ones such as being able to hold a conversation with a historical figure in virtual reality by creating visuals just from audio. This is the kind of breakthrough that will help enable those next steps.”
Using a TITAN X GPU and the cuDNN-accelerated TensorFlow deep learning framework, the researchers trained their recurrent neural network on 17 hours of Barack Obama footage to learn the mapping of raw audio features and mouth movements.
As described in their paper, they are then able to generated realistic video of the former president talking about terrorism, fatherhood, and other topics using audio clips of those speeches and existing weekly video addresses that were originally on a different topic.
The team used Obama because their neural nets needs hours of high-quality public video to learn from. “In the future video, chat tools like Skype or Messenger will enable anyone to collect videos that could be used to train computer models,” Kemelmacher-Shlizerman said.
Read more >
Related resources
- GTC session: Human-Like AI Voices: Exploring the Evolution of Voice Technology
- GTC session: Mastering Speech AI for Multilingual Multimedia Transformation
- GTC session: Generative AI Theater: AI Decoded - Generative AI Spotlight Art With RTX PCs and Workstations
- NGC Containers: Autovox Hindi ASR
- SDK: NVIDIA Tokkio
- Webinar: How Telcos Transform Customer Experiences with Conversational AI