In the field of computer vision (CV), an ongoing challenge is to build systems that can extract meaningful information from images as humans do, like distinguishing a street sign from a stop sign, or identifying lane boundaries. Evolving CV applications such as autonomous vehicles, like any deep learning problem, need a relevant dataset with which researchers can design useful neural networks and algorithms.
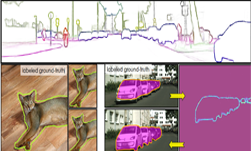
The Cityscapes dataset was created by Daimler AG R&D, Max Planck Institute for Informatics and TU Darmstadt Visual Inference Group to help autonomous vehicles better understand urban street scenes, and is comprised of 20,500 images from 50 European cities gathered during different seasons and weather conditions. The Cityscapes site also makes available benchmarks that focus on semantic labeling, a critical step to curating any dataset for use with neural networks. Data labeling is crucial when training a neural network, so that the network can correctly identify objects in a given image. One of the key metrics within these benchmarks is called semantic segmentation, a process that lets an autonomous vehicle’s “brain” better understand its surroundings, and detect and identify nearby objects.
Recently, a team from NVIDIA’s Applied Deep Learning Research team took over the number one spot for per-pixel semantic segmentation on the Cityscapes benchmark.

Semantic segmentation is an active area of research in the CV community, especially for autonomous vehicle applications. The Cityscape dataset is divided into 19 classes such as car, truck, bus, train, pedestrian, etc. so CV systems can more readily understand urban landscapes. The particular metric of interest is called Intersection Over Union (IOU), which indicates the similarity between the network prediction and the ground truth. The higher the IOU the better, and 100 IOU means perfect prediction. IOU is computed per class or per category, and can be averaged over the all the classes (mean-IOU). Mean-IOU is usually the comparison metric for semantic segmentation.
Getting to Number One
To improve performance on semantic segmentation, the NVIDIA’s Applied Deep Learning Research team used a network architecture derived from DeepLab V3+. The team’s solution combined aggressive data augmentation, along with methods to deal with class imbalance: class-specific weighting and class-uniform sampling to achieve 83.2 Mean-IOU, the best score ever recorded. The team also performed extensive hyperparameter tuning using Saturn V compute cluster, NVIDIA’s GPU-powered AI supercomputer powered by 5,280 Tesla V100 Tensor Core GPUs.
NVIDIA’s Applied Deep Learning Research team’s work in this field is ongoing, and in addition to owning the top spot for per-pixel semantic segmentation, the team has now set its sights set on the number one spot for per-instance semantic segmentation performance. This benchmark focuses on simultaneously detecting objects and segmenting them, which requires a set of detections of traffic participants in the scene, each associated with a confidence score.
For autonomous vehicle applications, safety is paramount, and a CV system’s ability to understand its surroundings is key to getting that vehicle and its occupants safely to their destination. This understanding comes from being able to quickly and correctly identify nearby objects (moving and stationary), and determine the required action to navigate safely.. NVIDIA continues to lead this area, not only with its DRIVE Pegasus AI platform for self-driving vehicles, but with advances in research working in conjunction with the autonomous vehicle developer community.
NVIDIA AI platforms deliver a powerful cloud-to-car solution, from NVIDIA DGX™ systems for training deep neural networks in the data center to NVIDIA DRIVE™ solutions that enable real-time, low-latency inferencing in the car for safer driving. To learn more, please visit nvidia.com/drive.