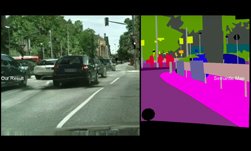
Researchers from MIT’s Computer Science and Artificial Intelligence Lab (CSAIL), ETH Zurich, and Adobe recently introduced a new deep learning-based tool that can automatically extract objects or people in the foreground from the background.
The solution offers an alternative to manually selecting an object in a photo and attempting to remove it the old-fashioned way.
“Accurate representation of soft transitions between image regions is essential for high-quality image editing and compositing. Current techniques for generating such representations depend heavily on interaction by a skilled visual artist, and creating such accurate object selections is a tedious task,” the researchers wrote on their paper.
To solve the problem, the team developed an automatic deep learning based method that can generate soft segments or layers that represent the semantically meaningful regions in an image and the soft transitions between them. The segments can then be used as masks for targeted image edits.
Using NVIDIA TITAN Xp GPUs and the cuDNN-accelerated TensorFlow deep learning framework, the team trained their generative adversarial network (GAN) on hundreds of images from the COCO-Stuff dataset.

“The tricky thing about these images is that not every pixel solely belongs to one object. In many cases it can be hard to determine which pixels are part of the background and which are part of a specific person,” MIT CSAIL researcher Yagiz Aksoy said. “We approach this problem from a spectral segmentation angle and propose a graph structure that embeds texture and color features from the image as well as higher-level semantic information generated by a neural network,” the team explained.
When compared to other approaches that aim to do the same, the method achieves a higher accuracy around edges and soft transitions, the team said.
The research was recently presented at the SIGGRAPH conference in Vancouver, Canada.
This AI Can Automatically Remove the Background from a Photo
Aug 22, 2018
Discuss (0)

Related resources
- GTC session: Scaling Generative AI Features to Millions of Users Thanks to Inference Pipeline Optimizations
- GTC session: Generative AI Theater: Generative AI Can Take You Anywhere
- GTC session: Generative AI Theater: AI Decoded - Generative AI Spotlight Art With RTX PCs and Workstations
- NGC Containers: MATLAB
- SDK: NVIDIA Texture Tools-Photoshop Plug in
- Webinar: Accelerate AI Model Inference at Scale for Financial Services