Keras is a powerful deep learning meta-framework which sits on top of existing frameworks such as TensorFlow and Theano. Keras is highly productive for developers; it often requires 50% less code to define a model than native APIs of deep learning frameworks require. This productivity has made it very popular as a university and MOOC teaching tool, and as a rapid prototyping platform for applied researchers and developers.
Unfortunately, Keras is quite slow in terms of single-GPU training and inference time (regardless of the backend). It is also hard to get it to work on multiple GPUs without breaking its framework-independent abstraction.
Can this be improved, leveraging Keras’s high-level API, while still achieving good single-GPU performance and multi-GPU scaling? It turns out that the answer is yes, thanks to the MXNet backend for Keras, and MXNet’s efficient data pipeline. Last week, the MXNet community introduced a release candidate for MXNet v0.11.0 with support for Keras v1.2.
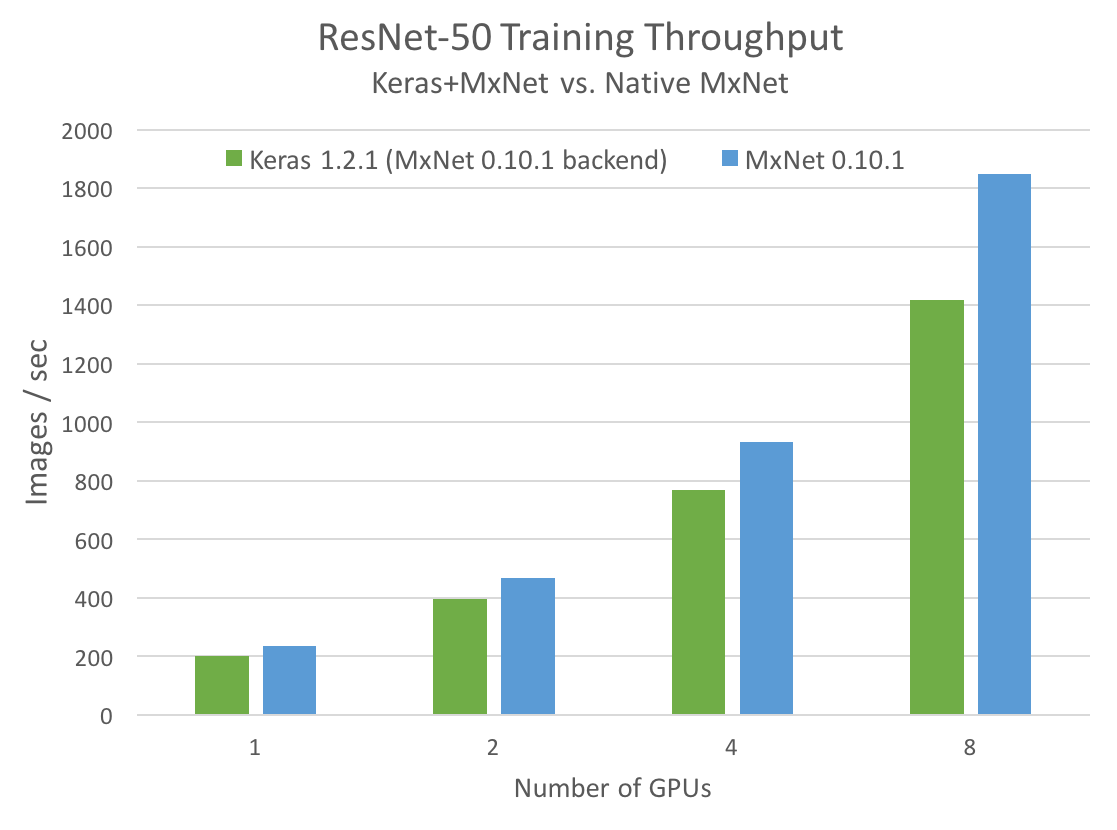
In a new NVIDIA Developer Blog post, Marek Kolodziej shows how to use Keras with the MXNet backend to achieve high performance and excellent multi-GPU scaling. As a motivating example, I’ll show you how to build a fast and scalable ResNet-50 model in Keras.
Read more >
Scaling Keras Model Training to Multiple GPUs
Aug 17, 2017
Discuss (0)

Related resources
- DLI course: Deep Learning at Scale with Horovod
- DLI course: Fundamentals of Deep Learning for Multi-GPUs
- GTC session: Multi GPU Programming Models for HPC and AI
- GTC session: Data Parallelism: How To Train Deep Learning Models on Multiple GPUs
- GTC session: Accelerate Recommender Systems and Increase GPU Utilization With Multiple CUDA Streams
- NGC Containers: NVIDIA NPN Workshop: Scaling Data Loading with DALI