Researchers at Ohio State University developed a GPU-accelerated program that can isolate speech from background noise and automatically adjust the volumes of each separately.
Less than 25 percent of people who need a hearing aid actually use one – with the greatest frustration among users is the hearing aid cannot distinguish sounds that occur at the same time, such as someone talking and a car driving by. The device turns the volume up on both.
Using CUDA, TITAN X and cuDNN with the TensorFlow deep learning framework, the researchers trained their models to extract features that could distinguish voices from noise based on common changes in amplitude, frequency, and the modulations of each – 85 attributes were identified.
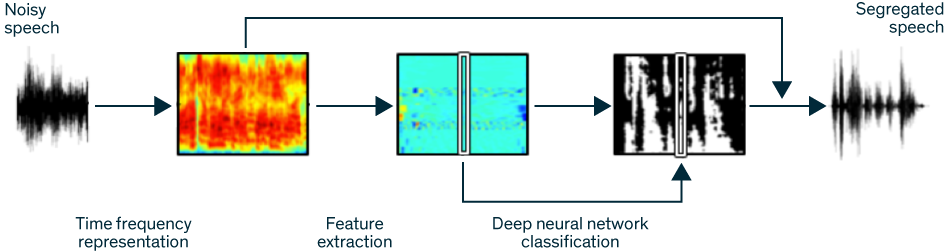
To test the program, the researchers asked 12 hearing-impaired people and 12 with normal hearing to listen through headphones to samples of noisy sentences. People in both grounds showed a huge improvement – several went from understanding only 10 percent of words to comprehending nearly 90 percent with the program. Even the people with normal hearing were able to better understand noisy sentences with the program.
The researchers mentioned the most intriguing result of the experiment was, could people with hearing impairment who are assisted by the deep learning-based program actually outperform those with normal hearing? And, the answer is yes.
Read more >
Reinventing the Hearing Aid with Deep Learning
Dec 08, 2016
Discuss (0)

Related resources
- GTC session: Using Deep Learning & Generative AI Models to Enable Audio & Content Workflows
- GTC session: Generative AI Theater: Rise Above the Noise and Talk to Our AI Chatbot
- GTC session: Live from GTC: A Conversation with DeepL
- NGC Containers: MATLAB
- Webinar: How Telcos Transform Customer Experiences with Conversational AI
- Webinar: How to Build and Deploy an AI Voice-Enabled Virtual Assistant for Financial Services Contact Centers