A defining feature of the new Volta GPU Architecture is its Tensor Cores, which give the Tesla V100 accelerator a peak throughput 12 times the 32-bit floating point throughput of the previous-generation Tesla P100.
Tesla V100’s Tensor Cores are programmable matrix-multiply-and-accumulate units that can deliver up to 125 Tensor TFLOPS for training and inference applications. The Tesla V100 GPU contains 640 Tensor Cores: 8 per SM. Tensor Cores and their associated data paths are custom-crafted to dramatically increase floating-point compute throughput at only modest area and power costs. Clock gating is used extensively to maximize power savings.
Tensor Cores are already supported for deep learning training either in a main release or via pull requests in many deep learning frameworks (including TensorFlow, PyTorch, MXNet, and Caffe2). For more information about enabling Tensor Cores when using these frameworks, check out the Mixed-Precision Training Guide. For deep learning inference the recent TensorRT 3 release also supports Tensor Cores.
A new NVIDIA Developer Blog post shows you how to use Tensor Cores in your own application using CUDA Libraries as well as how to program them directly in CUDA C++ device code.
Two CUDA libraries that use Tensor Cores are cuBLAS and cuDNN. cuBLAS uses Tensor Cores to speed up GEMM computations (GEMM is the BLAS term for a matrix-matrix multiplication); cuDNN uses Tensor Cores to speed up both convolutions and recurrent neural networks (RNNs).
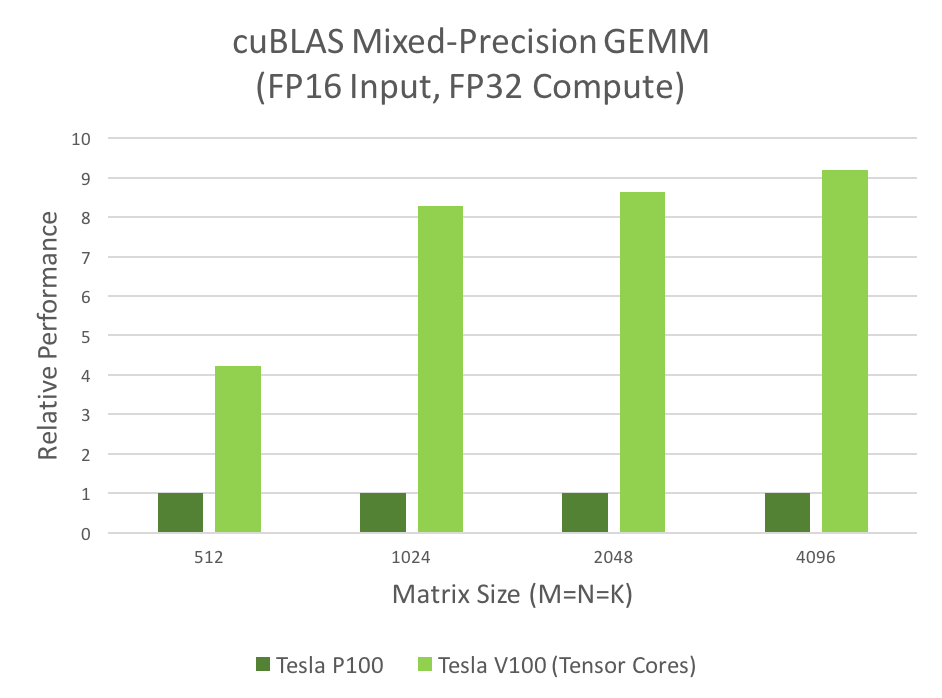
Many computational applications use GEMMs: signal processing, fluid dynamics, and many, many others. As the data sizes of these applications grow exponentially, these applications require matching increases in processing speed. The following mixed-precision GEMM performance chart shows that Tensor Cores clearly answer this need.
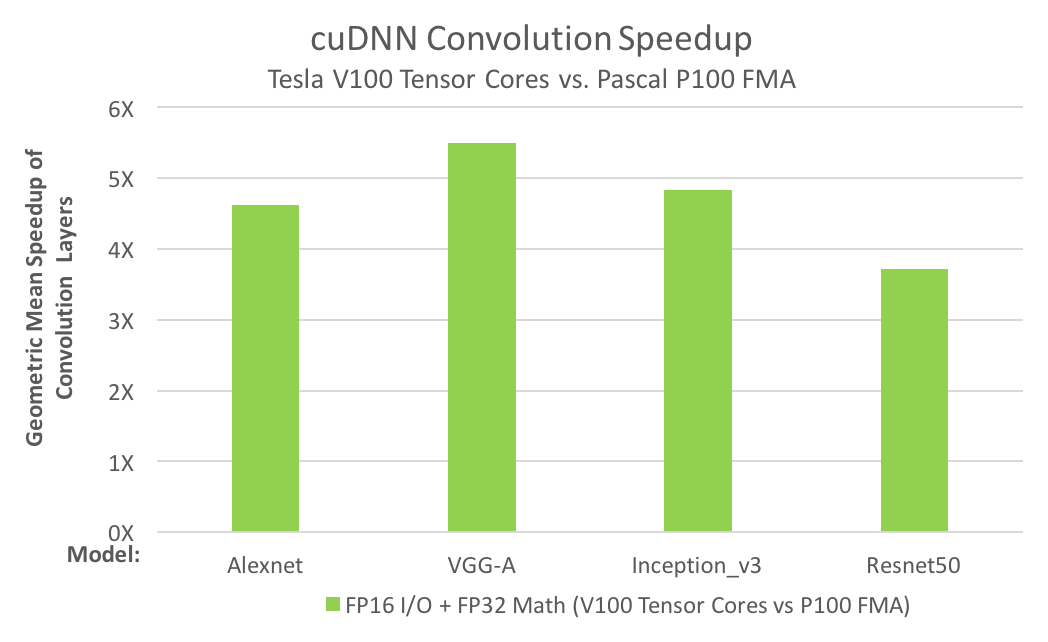
The need for convolution speed improvements is just as great; for example, today’s deep neural networks (DNNs) use many layers of convolutions. Artificial Intelligence researchers design deeper and deeper neural nets every year; the number of convolution layers in the deepest nets is now several dozen. Training DNNs requires the convolution layers to be run repeatedly, during both forward- and back-propagation. The following convolution performance chart shows that Tensor Cores answer the need for convolution performance.
Read more >
Related resources
- GTC session: CUTLASS: A Performant, Flexible, and Portable Way to Target Hopper Tensor Cores
- GTC session: CUTLASS: A Performant, Flexible, and Portable Way to Target Hopper Tensor Cores
- GTC session: Introduction to CUDA Programming and Performance Optimization
- GTC session: Introduction to CUDA Programming and Performance Optimization
- SDK: CUTLASS
- SDK: CUTLASS