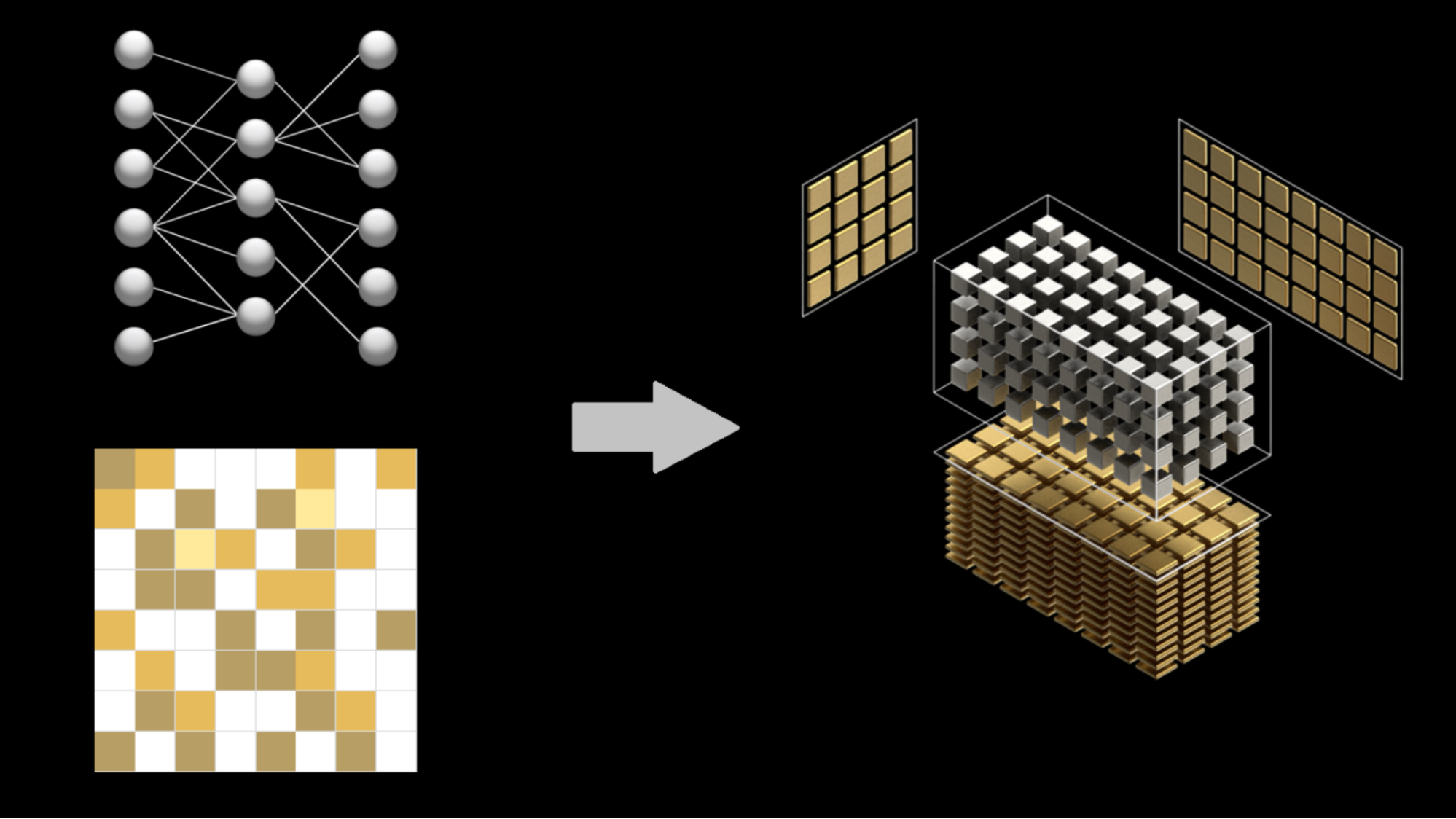
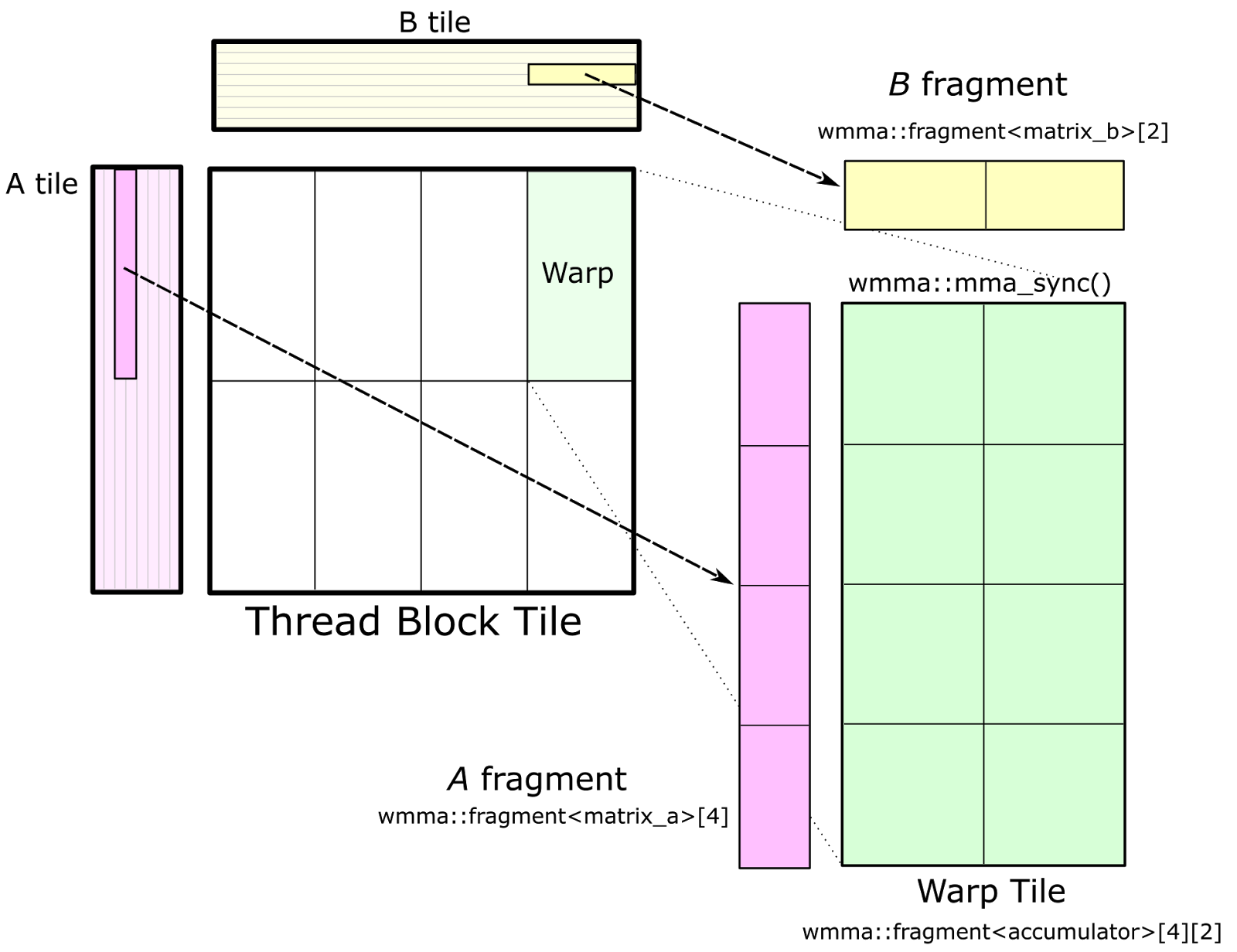
There’s a new computational workhorse in town. For decades, general matrix-matrix multiply—known as GEMM in Basic Linear Algebra Subroutines (BLAS) libraries—has been a standard benchmark for computational performance.
GEMM is possibly the most optimized and widely used routine in scientific computing. Expert implementations are available for every architecture and quickly achieve the peak performance of the machine. Recently, however, the performance of computing many small GEMMs has been a concern on some architectures.
A new Pro Tip post on the NVIDIA Parallel Forall blog by NVIDIA Researcher Cris Cecka details solutions now available in the cuBLAS library (CUDA Basic Linear Algebra Subroutines) for batched matrix multiply.
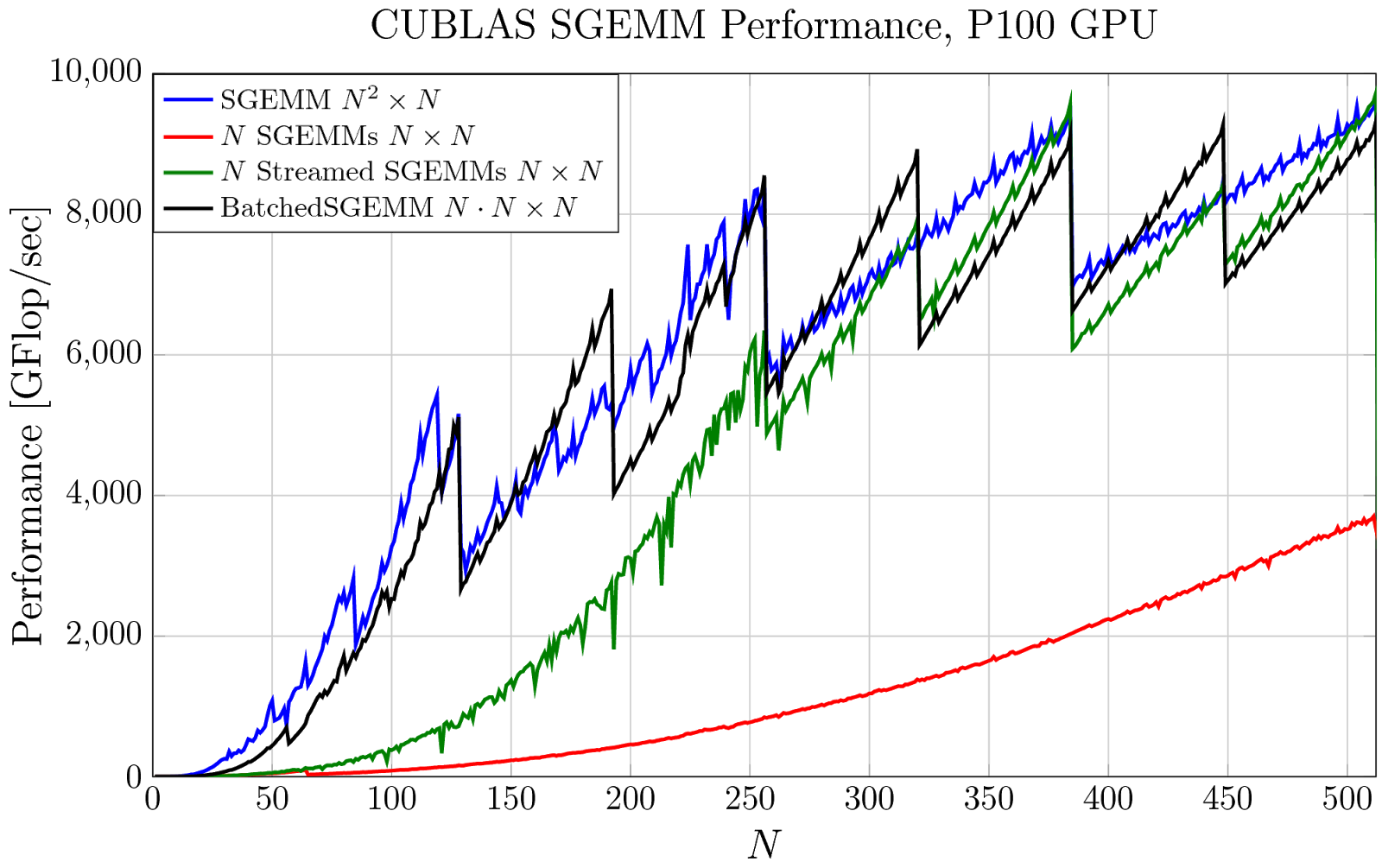
Cris shows how the new “strided batched GEMM” can be applied to efficient tensor contractions, an interesting application that users can now be confident will execute out-of-the-box with the full performance of a GPU. In a recent paper, Cris and his collaborators have shown how this new approach to computing many small matrix multiplies in parallel can be applied to applications in deep learning for higher efficiency.
Read more >
Pro Tip: cuBLAS Strided Batched Matrix Multiply
Feb 28, 2017
Discuss (0)