Researchers at NVIDIA open-sourced v0.2 of OpenSeq2Seq – a new toolkit built on top of TensorFlow for training sequence-to-sequence models. OpenSeq2Seq provides researchers with optimized implementation of various sequence-to-sequence models commonly used for applications such as machine translation and speech recognition.
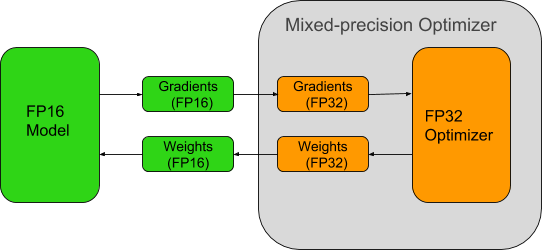
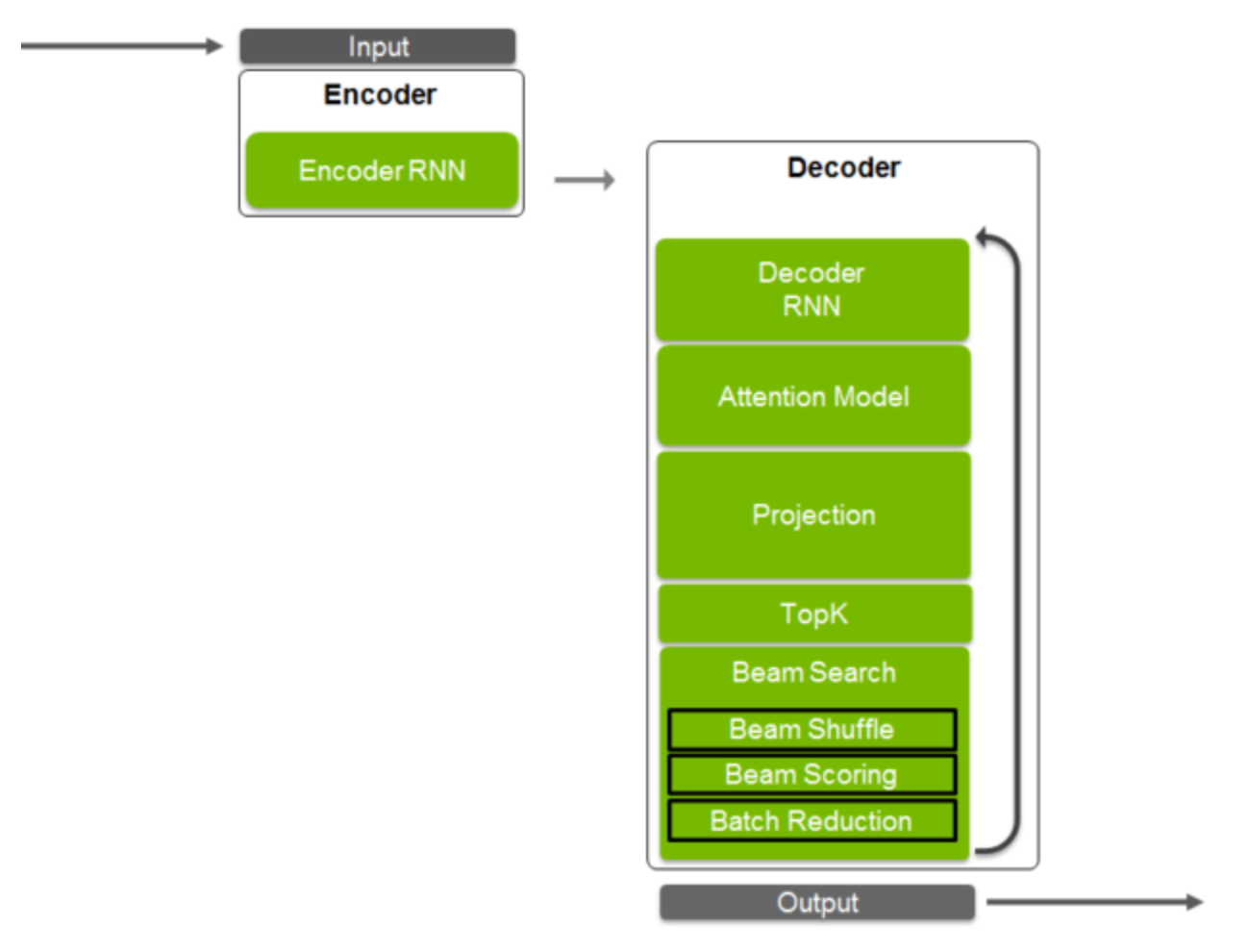
OpenSeq2Seq is performance optimized for mixed-precision training using Tensor Cores on NVIDIA Volta GPUs. With support for efficient multi-GPU and multi-node training, researchers can train models faster and with larger datasets. Built on TensorFlow deep learning framework, OpenSeq2Seq provides all the necessary building blocks for training encoder-decoder models for neural machine translation and automatic speech recognition. Since it’s designed to allow easy experimentation, researchers can easily extend OpenSeq2Seq to support novel architectures. In the future OpenSeq2Seq will be extended to support other input-output modalities.
OpenSeq2Seq highlights includes:
- Optimized for NVIDIA Volta GPUs with built-in support for Tensor Core mixed-precision training
- Train models for machine translation and speech recognition applications using standard sequence-to-sequence, and speech-to-text and text-to-text models
- Pre-defined encoder and decoders for popular DeepSpeech2, NMT, GNMT, Transformers architectures
- Modular design for experimenting with novel encoder-decoder architectures (e.g. CNN-based encoder with RNN-based decoder and other combinations.)
- Faster training with multi-GPU and multi-node (using Horovod) distributed training
Installation and getting started instructions:
https://nvidia.github.io/OpenSeq2Seq/html/installation.html#installation
OpenSeq2Seq source-code:
https://github.com/NVIDIA/OpenSeq2Seq
Give it a try and please comment below with feedback.