AI has become a crucial technology for end user applications and services. The daily interactions we have with search engines, voice assistants, recommender applications, and more, all use AI models to derive their particular form of insight.
When using AI in an application, it is necessary to perform ‘inference’ on trained AI models — in other words, the trained model is used to provide answers to the questions the application asks. In most cases, inference is performed in the data center, independent of the application, and the result is sent to the application over the network.
Just as a web server serves web pages, an inference server serves inference. And just as web servers, application servers, and database servers have evolved to use technologies such as Docker and Kubernetes to work together seamlessly in production deployments, an inference server should do the same.
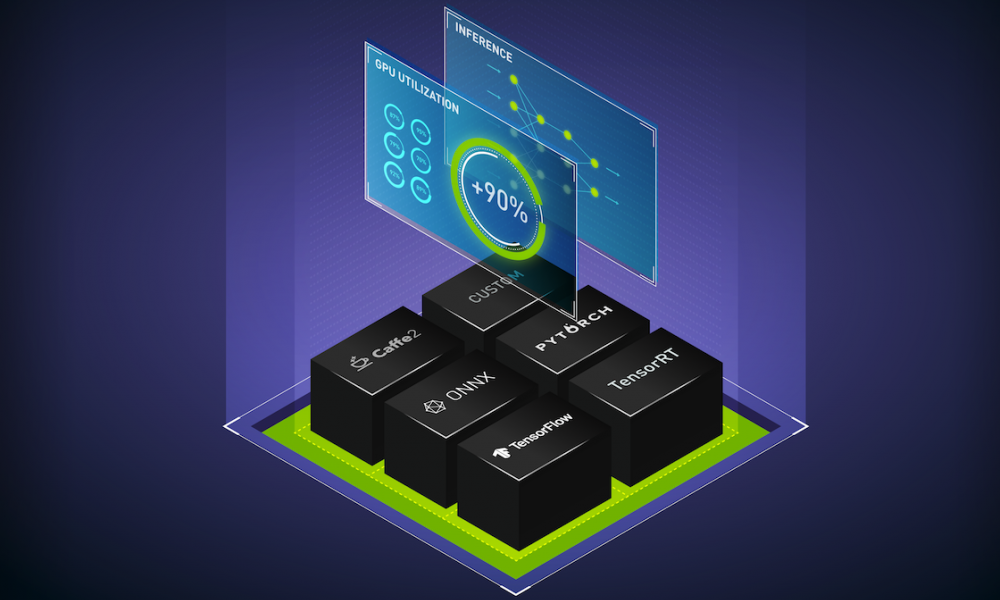
The new NVIDIA TensorRT inference server is a containerized microservice for performing GPU-accelerated inference on trained AI models in the data center. It maximizes GPU utilization by supporting multiple models and frameworks, single and multiple GPUs, and batching of incoming requests. It’s designed for DevOps, leveraging containers and providing metrics for dynamic Kubernetes architectures.
A very popular tool for deploying software in Kubernetes production environments is Kubeflow. In their words, “Our goal is to make scaling machine learning (ML) models and deploying them to production as simple as possible.” Now, Kubeflow and NVIDIA are working together to make it easy to deploy inference into Kubernetes environments.
David Aronchick, co-founder and product manager of Kubeflow, stated: “We are excited to see NVIDIA bring GPU inference to Kubernetes with the NVIDIA TensorRT inference server, and look forward to integrating it with Kubeflow to provide users with a simple, portable and scalable way to deploy AI inference across diverse infrastructures.”
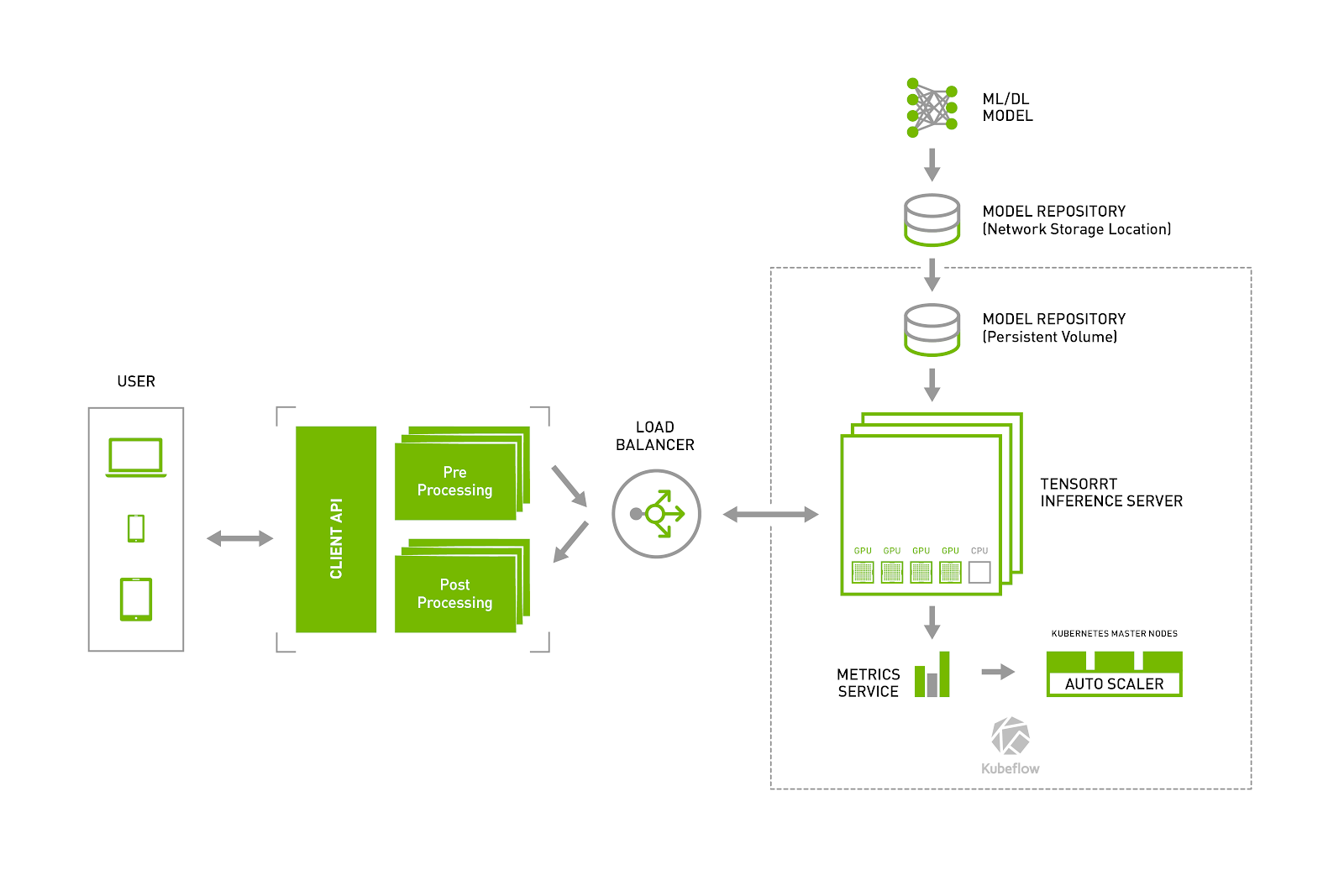
The combination of the TensorRT inference server and Kubeflow make data center production using AI inference repeatable and scalable. This integration allows DevOps engineers to use
the tools they are already familiar with to add high performance GPU-accelerated inference services into their production stacks.
Learn more about the TensorRT inference server
Learn more about Kubeflow
Learn how to use the NVIDIA TensorRT inference server and Kubeflow together
NVIDIA TensorRT Inference Server and Kubeflow Make Deploying Data Center Inference Simple
Sep 14, 2018
Discuss (0)

Related resources
- DLI course: Deploying a Model for Inference at Production Scale
- GTC session: Accelerate Smart City Edge AI Deployment With Open-Source Cloud-Native Infrastructure
- GTC session: Scaling Global Cloud Inference With NVIDIA GH200 and NVIDIA AI Enterprise (Presented by Vultr)
- GTC session: Inference at the Edge: Building a Global, Scalable AI Inference Network (Presented by Cloudflare)
- SDK: Triton Management Service
- SDK: TensorFlow-TensorRT