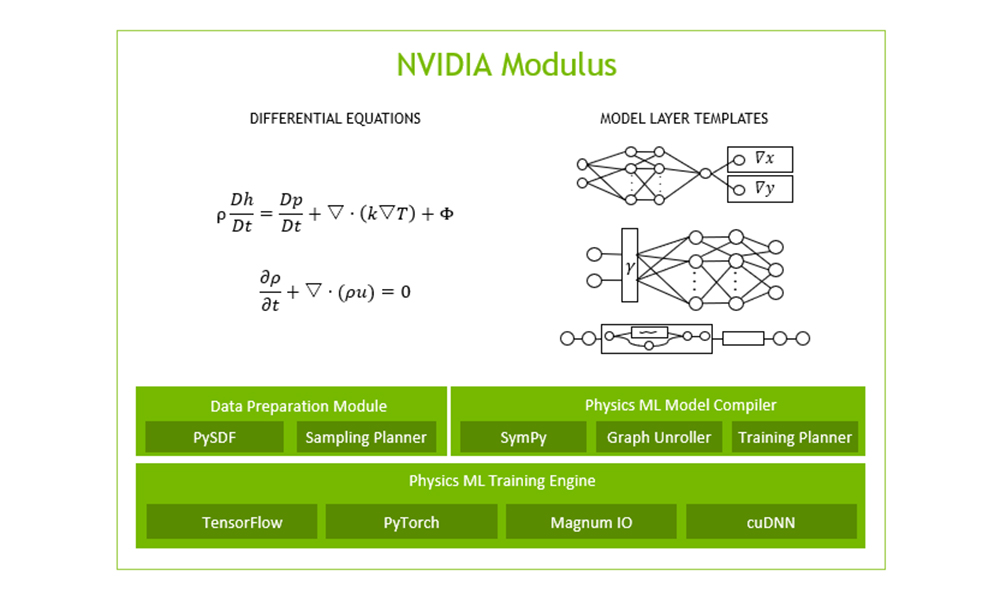
NVIDIA Modulus was previously known as NVIDIA SimNet.
Today, NVIDIA announced the release of Modulus v0.2 with new features, including support for A100 GPUs and multi-GPU/multi-node, as well as adding a larger set of neural network architectures and a greater solution space addressability. These new features allow you to advance simulations for more advanced physics like turbulence and work with complex geometries.
Previously announced in May, NVIDIA Modulus is a physics-informed neural network (PINN) toolkit for students and researchers who are either looking to get started with AI-driven physics simulations or are looking to leverage a powerful framework to implement their domain knowledge to solve complex nonlinear physics problems with real-world applications.
Here are some of the Modulus v0.2 highlights.
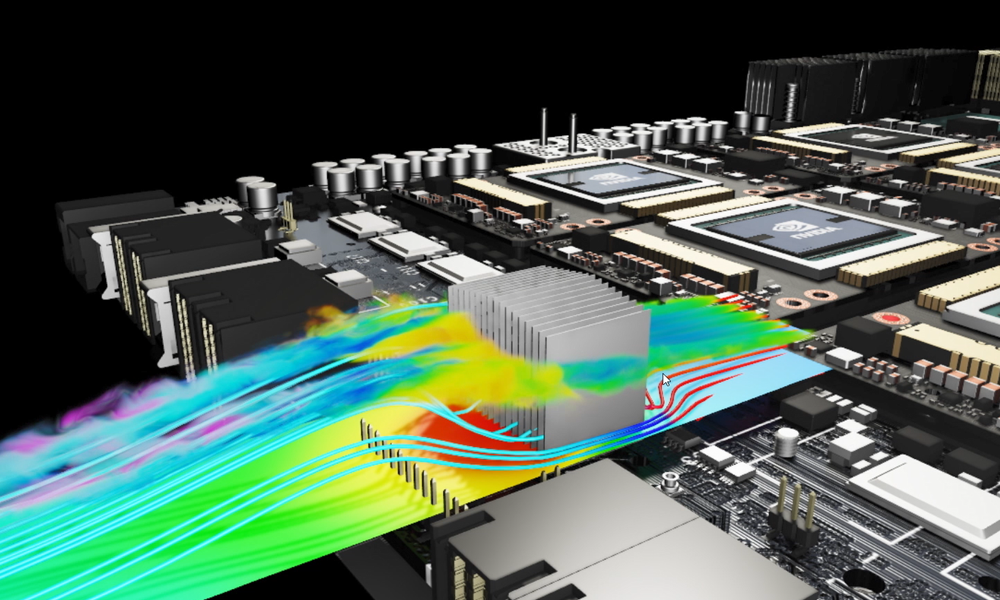
Turbulent simulations with high Reynold numbers
Simulation of complex geometries is difficult for standard fully connected networks even with some of the previously introduced losses like integral losses and SDF weighting. Modulus v0.2 introduces new networks such as Fourier features and its variants, SiReNs, DGM as well as features like global and local adaptive learning rate annealing, global activation functions, exact continuity or mass balance for flow problems and Halton sequences for low discrepancy point cloud that facilitate the exploration of more complex shapes and physics like turbulence modeling in CFD.
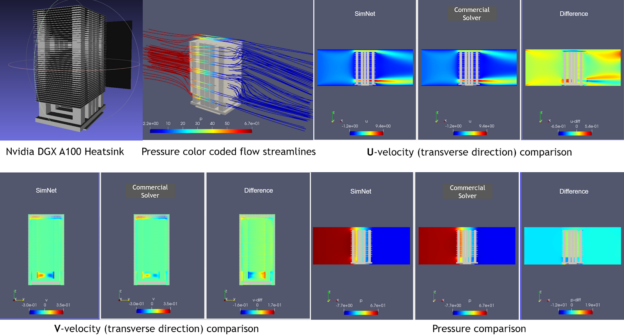
Real world geometries
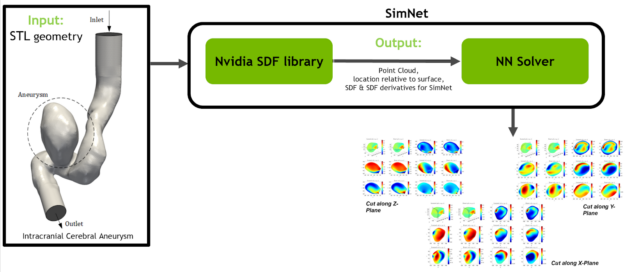
In addition to the Modulus geometry library that allowed building objects with primitive shapes, a new SDF library in Modulus v0.2 now enables import of STL geometries from CAD packages to work with complex geometries.
Performance
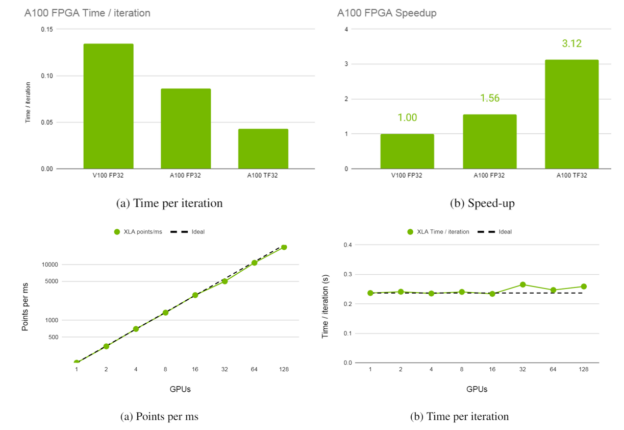
SimNet v0.2 is highly scalable for multi-GPU and multinode. In a scalability study using 16 DGX-1 with 128 NVIDIA V100 GPUs, the scalability for points processed per second remained linear with a near constant time per iteration. Modulus is also supported on NVIDIA A100 GPUs now and leverages the TF32 precision. An initial study shows the A100 with TF32 to be faster ~2x compared to FP32 precision and about ~3x compared to V100 without significant difference in accuracy.
Give it a try by requesting Modulus access today.