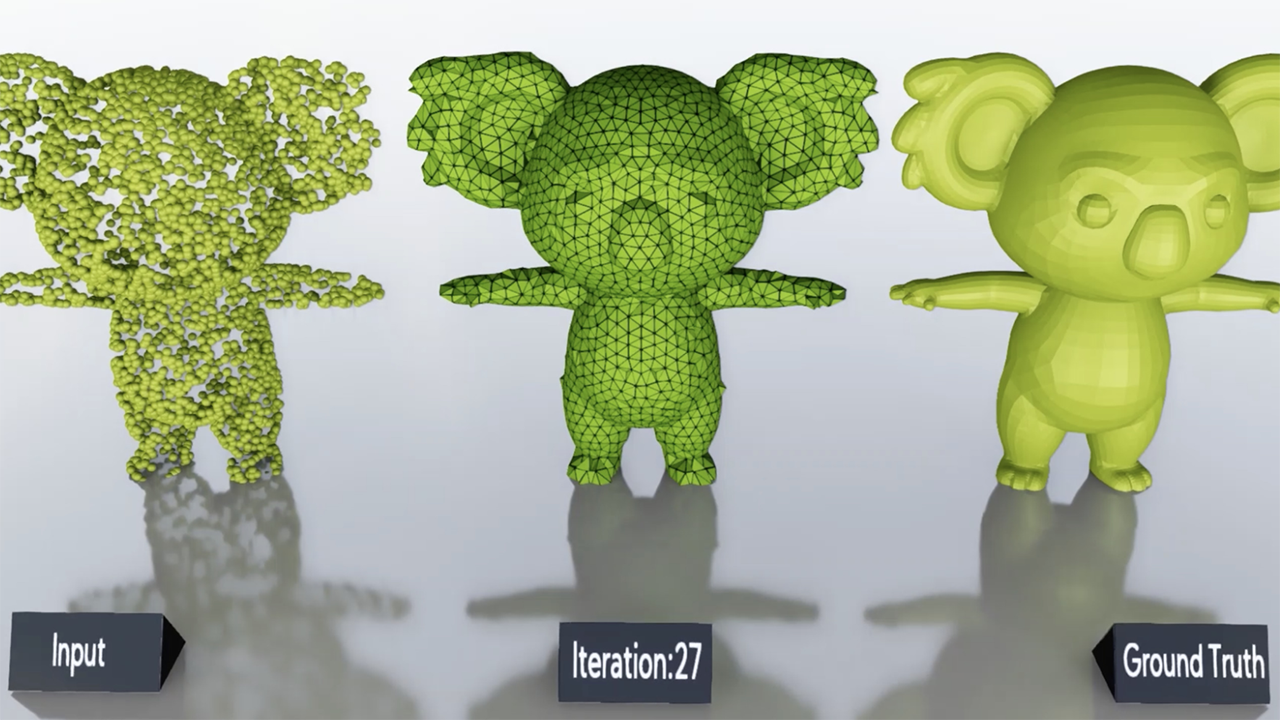
NVIDIA Researchers will present 19 accepted papers and posters, seven of them speaking sessions, at the annual Computer Vision and Pattern Recognition (CVPR) conference June 18 – 22 in Salt Lake City, Utah.

Speaking Sessions
SPLATNet: Sparse Lattice Networks for Point Cloud Processing
Hang Su, Varun Jampani, Deqing Sun, Subhransu Maji, Evangelos Kalogerakis, Ming-Hsuan Yang, Jan Kautz
Tues, June 19 2:50 – 4:30 PM, Room 155
Abstract: We present a network architecture for processing point clouds that directly operates on a collection of points represented as a sparse set of samples in a high-dimensional lattice. Naively applying convolutions on this lattice scales poorly, both in terms of memory and computational cost, as the size of the lattice increases. Instead, our network uses sparse bilateral convolutional layers as building blocks. These layers maintain efficiency by using indexing structures to apply convolutions only on occupied parts of the lattice, and allow flexible specifications of the lattice structure enabling hierarchical and spatially-aware feature learning, as well as joint 2D-3D reasoning. Both point-based and image-based representations can be easily incorporated in a network with such layers and the resulting model can be trained in an end-to-end manner. We present results on 3D segmentation tasks where our approach outperforms existing state-of-the-art techniques.
Read the paper: https://arxiv.org/abs/1802.08275
Depth-Based 3D Hand Pose Estimation: From Current Achievements to Future Goals
Shanxin Yuan, Guillermo Garcia-Hernando, Bjorn Stenger, Gyeongsik Moon, Ju Yong Chang, Kyoung Mu Lee, Pavlo Molchanov, Jan Kautz, Sina Honari, Liuhao Ge, Junsong Yuan, Xinghao Chen, Guijin Wang, Fan Yang, Kai Akiyama, Yang Wu, Qingfu Wan, Meysam Madadi, Sergio Escalera, Shile Li, Dongheui Lee, Iason Oikonomidis, Antonis Argyros, Tae-Kyun Kim
Tues, June 19 2:50 – 4:30 PM, Room 155
Abstract: In this paper, we strive to answer two questions: What is the current state of 3D hand pose estimation from depth images? And, what are the next challenges that need to be tackled? Following the successful Hands In the Million Challenge (HIM2017), we investigate the top 10 state-of-the-art methods on three tasks: single frame 3D pose estimation, 3D hand tracking, and hand pose estimation during object interaction. We analyze the performance of different CNN structures with regard to hand shape, joint visibility, view point and articulation distributions. Our findings include: (1) isolated 3D hand pose estimation achieves low mean errors (10 mm) in the view point range of [70, 120] degrees, but it is far from being solved for extreme view points; (2) 3D volumetric representations outperform 2D CNNs, better capturing the spatial structure of the depth data; (3) Discriminative methods still generalize poorly to unseen hand shapes; (4) While joint occlusions pose a challenge for most methods, explicit modeling of structure constraints can significantly narrow the gap between errors on visible and occluded joints.
Read the paper: https://arxiv.org/abs/1712.03917
Geometry-Aware Learning of Maps for Camera Localization
Samarth Brahmbhatt, Jinwei Gu, Kihwan Kim, James Hays, Jan Kautz
Tues, June 19 2:50 – 4:30 PM, Room 155
Abstract: Maps are a key component in image-based camera localization and visual SLAM systems: they are used to establish geometric constraints between images, correct drift in relative pose estimation, and relocalize cameras after lost tracking. The exact definitions of maps, however, are often application-specific and hand-crafted for different scenarios (e.g. 3D landmarks, lines, planes, bags of visual words). We propose to represent maps as a deep neural net called MapNet, which enables learning a data-driven map representation. Unlike prior work on learning maps, MapNet exploits cheap and ubiquitous sensory inputs like visual odometry and GPS in addition to images and fuses them together for camera localization. Geometric constraints expressed by these inputs, which have traditionally been used in bundle adjustment or pose-graph optimization, are formulated as loss terms in MapNet training and also used during inference. In addition to directly improving localization accuracy, this allows us to update the MapNet (i.e., maps) in a self-supervised manner using additional unlabeled video sequences from the scene. We also propose a novel parameterization for camera rotation which is better suited for deep-learning based camera pose regression. Experimental results on both the indoor 7-Scenes dataset and the outdoor Oxford RobotCar dataset show significant performance improvement over prior work.
Read the paper: https://arxiv.org/abs/1712.03342
PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume
Deqing Sun, Xiaodong Yang, Ming-Yu Liu, Jan Kautz
Thurs, June 21 2:50 – 4:30 PM, Room 155
Abstract: We present a compact but effective CNN model for optical flow, called PWC-Net. PWC-Net has been designed according to simple and well-established principles: pyramidal processing, warping, and the use of a cost volume. Cast in a learnable feature pyramid, PWC-Net uses the current optical flow estimate to warp the CNN features of the second image. It then uses the warped features and features of the first image to construct the cost volume, which is processed by a CNN to estimate the optical flow. PWCNet is 17 times smaller in size and easier to train than the recent FlowNet2 model. Moreover, it outperforms all published methods on the MPI Sintel final pass and KITTI 2015 benchmarks, running at about 35 fps on Sintel resolution (1024×436) images. Our model will be publicly available.
Read the paper: https://arxiv.org/abs/1709.02371
Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation
Huaizu Jiang, Deqing Sun, Varun Jampani, Ming-Hsuan Yang, Erik Learned-Miller, Jan Kautz
Thurs, June 21 2:50 – 4:30 PM, Room 155
Abstract: Given two consecutive frames, video interpolation aims at generating intermediate frame(s) to form both spatially and temporally coherent video sequences. While most existing methods focus on single-frame interpolation, we propose an end-to-end convolutional neural network for variable-length multi-frame video interpolation, where the motion interpretation and occlusion reasoning are jointly modeled. We start by computing bi-directional optical flow between the input images using a U-Net architecture. These flows are then linearly combined at each time step to approximate the intermediate bi-directional optical flows. These approximate flows, however, only work well in locally smooth regions and produce artifacts around motion boundaries. To address this shortcoming, we employ another U-Net to refine the approximated flow and also predict soft visibility maps. Finally, the two input images are warped and linearly fused to form each intermediate frame. By applying the visibility maps to the warped images before fusion, we exclude the contribution of occluded pixels to the interpolated intermediate frame to avoid artifacts. Since none of our learned network parameters are time-dependent, our approach is able to produce as many intermediate frames as needed. We use 1,132 video clips with 240-fps, containing 300K individual video frames, to train our network. Experimental results on several datasets, predicting different numbers of interpolated frames, demonstrate that our approach performs consistently better than existing methods.
Read the paper: https://arxiv.org/abs/1712.00080
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, Bryan Catanzaro
Thurs, June 21 2:50 – 4:30 PM, Ballroom
Abstract: We present a new method for synthesizing high-resolution photo-realistic images from semantic label maps using conditional generative adversarial networks (conditional GANs). Conditional GANs have enabled a variety of applications, but the results are often limited to low-resolution and still far from realistic. In this work, we generate 2048×1024 visually appealing results with a novel adversarial loss, as well as new multi-scale generator and discriminator architectures. Furthermore, we extend our framework to interactive visual manipulation with two additional features. First, we incorporate object instance segmentation information, which enables object manipulations such as removing/adding objects and changing the object category. Second, we propose a method to generate diverse results given the same input, allowing users to edit the object appearance interactively. Human opinion studies demonstrate that our method significantly outperforms existing methods, advancing both the quality and the resolution of deep image synthesis and editing.
Read the paper: https://arxiv.org/abs/1711.11585
TieNet: Text-Image Embedding Network for Common Thorax Disease Classification and Reporting in Chest X-rays
Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Ronald M. Summers
Thurs, June 21 2:50 – 4:30 PM, Room 155
Abstract: Chest X-rays are one of the most common radiological examinations in daily clinical routines. Reporting thorax diseases using chest X-rays is often an entry-level task for radiologist trainees. Yet, reading a chest X-ray image remains a challenging job for learning-oriented machine intelligence, due to (1) shortage of large-scale machine-learnable medical image datasets, and (2) lack of techniques that can mimic the high-level reasoning of human radiologists that requires years of knowledge accumulation and professional training. In this paper, we show the clinical free-text radiological reports can be utilized as a priori knowledge for tackling these two key problems. We propose a novel Text-Image Embedding network (TieNet) for extracting the distinctive image and text representations. Multi-level attention models are integrated into an end-to-end trainable CNN-RNN architecture for highlighting the meaningful text words and image regions. We first apply TieNet to classify the chest X-rays by using both image features and text embeddings extracted from associated reports. The proposed auto-annotation framework achieves high accuracy (over 0.9 on average in AUCs) in assigning disease labels for our hand-label evaluation dataset. Furthermore, we transform the TieNet into a chest X-ray reporting system. It simulates the reporting process and can output disease classification and a preliminary report together. The classification results are significantly improved (6% increase on average in AUCs) compared to the state-of-the-art baseline on an unseen and hand-labeled dataset (OpenI).
Read the paper: https://arxiv.org/abs/1801.04334
Papers & Posters
Learning Superpixels with Segmentation-Aware Affinity Loss
Wei-Chih Tu, Ming-Yu Liu, Varun Jampani, Deqing Sun, Shao-Yi Chien, Ming-Hsuan Yang, Jan Kautz
Tues, June 19 10:10 AM – 12:30 PM, Hall C-E
Abstract: Superpixel segmentation has been widely used in many computer vision tasks. Existing superpixel algorithms are mainly based on hand-crafted features, which often fail to preserve weak object boundaries. In this work, we leverage deep neural networks to facilitate extracting superpixels from images. We show a simple integration of deep features with existing superpixel algorithms does not result in better performance as these features do not model segmentation. Instead, we propose a segmentation-aware affinity learning approach for superpixel segmentation. Specifically, we propose a new loss function that takes the segmentation error into account for affinity learning. We also develop the Pixel Affinity Net for affinity prediction. Extensive experimental results show that the proposed algorithm based on the learned segmentation-aware loss performs favorably against the state-of-the-art methods. We also demonstrate the use of the learned superpixels in numerous vision applications with consistent improvements.
MoCoGAN: Decomposing Motion and Content for Video Generation
Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang, Jan Kautz
Tues, June 19 12:30 – 2:50 PM, Hall C-E
Abstract: Visual signals in a video can be divided into content and motion. While content specifies which objects are in the video, motion describes their dynamics. Based on this prior, we propose the Motion and Content decomposed Generative Adversarial Network (MoCoGAN) framework for video generation. The proposed framework generates a video by mapping a sequence of random vectors to a sequence of video frames. Each random vector consists of a content part and a motion part. While the content part is kept fixed, the motion part is realized as a stochastic process. To learn motion and content decomposition in an unsupervised manner, we introduce a novel adversarial learning scheme utilizing both image and video discriminators. Extensive experimental results on several challenging datasets with qualitative and quantitative comparison to the state-of-the-art approaches, verify effectiveness of the proposed framework. In addition, we show that MoCoGAN allows one to generate videos with same content but different motion as well as videos with different content and same motion.
Read the paper: https://arxiv.org/abs/1707.04993
Improving Landmark Localization with Semi-Supervised Learning
Sina Honari, Pavlo Molchanov, Stephen Tyree, Pascal Vincent, Christopher Pal, Jan Kautz
Tues, June 19 12:30 – 2:50 PM, Hall C-E
Abstract: We present two techniques to improve landmark localization in images from partially annotated datasets. Our primary goal is to leverage the common situation where precise landmark locations are only provided for a small data subset, but where class labels for classification or regression tasks related to the landmarks are more abundantly available. First, we propose the framework of sequential multitasking and explore it here through an architecture for landmark localization where training with class labels acts as an auxiliary signal to guide the landmark localization on unlabeled data. A key aspect of our approach is that errors can be back propagated through a complete landmark localization model. Second, we propose and explore an unsupervised learning technique for landmark localization based on having a model predict equivariant landmarks with respect to transformations applied to the image. We show that these techniques, improve landmark prediction considerably and can learn effective detectors even when only a small fraction of the dataset has landmark labels. We present results on two toy datasets and four real datasets, with hands and faces, and report new state-of-the-art on two datasets in the wild, e.g. with only 5\% of labeled images we outperform previous state-of-the-art trained on the AFLW dataset.
Read the paper: https://arxiv.org/abs/1709.01591
Making Convolutional Networks Recurrent for Visual Sequence Learning
Xiaodong Yang, Pavlo Molchanov, Jan Kautz
Wed, June 20 4:30 – 6:30 PM, Hall C-E
Abstract: Recurrent neural networks (RNNs) have emerged as a powerful model for a broad range of machine learning problems that involve sequential data. While an abundance of work exists to understand and improve RNNs in the context of language and audio signals such as language modeling and speech recognition, relatively little attention has been paid to analyze or modify RNNs for visual sequences, which by nature have distinct properties. In this paper, we aim to bridge this gap and present the first large-scale exploration of RNNs for visual sequence learning. In particular, with the intention of leveraging the strong generalization capacity of pre-trained convolutional neural networks (CNNs), we propose a novel and effective approach, Pre- RNN, to make pre-trained CNNs recurrent by transforming convolutional layers or fully connected layers into recurrent layers. We conduct extensive evaluations on three representative visual sequence learning tasks: sequential face alignment, dynamic hand gesture recognition, and action recognition. Our experiments reveal that PreRNN consistently outperforms the traditional RNNs and achieves state- of-the-art results on the three applications, suggesting that PreRNN is more suitable for visual sequence learning.
Read the paper: http://xiaodongyang.org/publications/papers/prernn-cvpr18.pdf
Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks
Jason Kuen, Xiangfei Kong, Zhe Lin, Gang Wang, Jianxiong Yin, Simon See, Yap-Peng Tan
Thurs, June 21 10:10 AM – 12:30 PM, Hall D-E
Abstract: It is desirable to train convolutional networks (CNNs) to run more efficiently during inference. In many cases however, the computational budget that the system has for inference cannot be known beforehand during training, or the inference budget is dependent on the changing real-time resource availability. Thus, it is inadequate to train just inference-efficient CNNs, whose inference costs are not adjustable and cannot adapt to varied inference budgets. We propose a novel approach for cost-adjustable inference in CNNs – Stochastic Downsampling Point (SDPoint). During training, SDPoint applies feature map downsampling to a random point in the layer hierarchy, with a random downsampling ratio. The different stochastic downsampling configurations known as SDPoint instances (of the same model) have computational costs different from each other, while being trained to minimize the same prediction loss. Sharing network parameters across different instances provides significant regularization boost. During inference, one may handpick a SDPoint instance that best fits the inference budget. The effectiveness of SDPoint, as both a cost-adjustable inference approach and a regularizer, is validated through extensive experiments on image classification.
Read the paper: https://arxiv.org/abs/1801.09335
Deep Semantic Face Deblurring
Ziyi Shen, Wei-Sheng Lai, Tingfa Xu, Jan Kautz, Ming-Hsuan Yang
Thurs, June 21 10:10 AM – 12:30 PM, Hall D-E
Abstract: In this paper, we present an effective and efficient face deblurring algorithm by exploiting semantic cues via deep convolutional neural networks (CNNs). As face images are highly structured and share several key semantic components (e.g., eyes and mouths), the semantic information of a face provides a strong prior for restoration. As such, we propose to incorporate global semantic priors as input and impose local structure losses to regularize the output within a multi-scale deep CNN. We train the network with perceptual and adversarial losses to generate photo-realistic results and develop an incremental training strategy to handle random blur kernels in the wild. Quantitative and qualitative evaluations demonstrate that the proposed face deblurring algorithm restores sharp images with more facial details and performs favorably against state-of-the-art methods in terms of restoration quality, face recognition and execution speed.
Read the paper: https://arxiv.org/abs/1803.03345
Deep Lesion Graphs in the Wild: Relationship Learning and Organization of Significant Radiology Image Findings in a Diverse Large-scale Lesion Database
Ke Yan, Xiaosong Wang, Le Lu, Ling Zhang, Adam Harrison, Mohammadhad Bagheri, Ronald Summers
Thurs, June 21 4:30 – 6:30 PM, Hall D-E
Abstract: Radiologists in their daily work routinely find and annotate significant abnormalities on a large number of radiology images. Such abnormalities, or lesions, have collected over years and stored in hospitals’ picture archiving and communication systems. However, they are basically unsorted and lack semantic annotations like type and location. In this paper, we aim to organize and explore them by learning a deep feature representation for each lesion. A large-scale and comprehensive dataset, DeepLesion, is introduced for this task. DeepLesion contains bounding boxes and size measurements of over 32K lesions. To model their similarity relationship, we leverage multiple supervision information including types, self-supervised location coordinates and sizes. They require little manual annotation effort but describe useful attributes of the lesions. Then, a triplet network is utilized to learn lesion embeddings with a sequential sampling strategy to depict their hierarchical similarity structure. Experiments show promising qualitative and quantitative results on lesion retrieval, clustering, and classification. The learned embeddings can be further employed to build a lesion graph for various clinically useful applications. We propose algorithms for intra-patient lesion matching and missing annotation mining. Experimental results validate their effectiveness.
Read the paper: https://arxiv.org/abs/1711.10535
Workshops
Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization
CVPR workshop on autonomous driving (WAD)
Jonathan Tremblay, Aayush Prakash, David Acuna, Mark Brophy, Varun Jampani, Cem Anil, Thang To, Stan Birchfield
Presentation: Monday, June 18th (time TBD)
Abstract: We present a system for training deep neural networks for object detection using synthetic images. To handle the variability in real-world data, the system relies upon the technique of domain randomization, in which the parameters of the simulator−such as lighting, pose, object textures, etc.−are randomized in non-realistic ways to force the neural network to learn the essential features of the object of interest. We explore the importance of these parameters, showing that it is possible to produce a network with compelling performance using only non-artistically-generated synthetic data. With additional fine-tuning on real data, the network yields better performance than using real data alone. This result opens up the possibility of using inexpensive synthetic data for training neural networks while avoiding the need to collect large amounts of hand-annotated real-world data or to generate high-fidelity synthetic worlds−both of which remain bottlenecks for many applications. The approach is evaluated on bounding box detection of cars on the KITTI dataset.
Read the paper: https://arxiv.org/abs/1804.06516
On the Importance of Stereo for Accurate Depth Estimation: An Efficient Semi-Supervised Deep Neural Network Approach
CVPR workshop on autonomous driving (WAD)
Nikolai Smolyanskiy, Alexey Kamenev, Stan Birchfield
Presentation: Monday, June 18 (time TBD)
Abstract: We revisit the problem of visual depth estimation in the context of autonomous vehicles. Despite the progress on monocular depth estimation in recent years, we show that the gap between monocular and stereo depth accuracy remains large−a particularly relevant result due to the prevalent reliance upon monocular cameras by vehicles that are expected to be self-driving. We argue that the challenges of removing this gap are significant, owing to fundamental limitations of monocular vision. As a result, we focus our efforts on depth estimation by stereo. We propose a novel semi-supervised learning approach to training a deep stereo neural network, along with a novel architecture containing a machine-learned argmax layer and a custom runtime (that will be shared publicly) that enables a smaller version of our stereo DNN to run on an embedded GPU. Competitive results are shown on the KITTI 2015 stereo dataset. We also evaluate the recent progress of stereo algorithms by measuring the impact upon accuracy of various design criteria.
Read the paper: https://arxiv.org/abs/1803.09719
Falling Things: A Synthetic Dataset for 3D Object Detection and Pose Estimation
CVPR Workshop on Real World Challenges and New Benchmarks for Deep Learning in Robotic Vision
Jonathan Tremblay, Thang To, Stan Birchfield
Presentation: Friday, June 22 (time TBD)
Abstract: We present a new dataset, called Falling Things (FAT), for advancing the state-of-the-art in object detection and 3D pose estimation in the context of robotics. By synthetically combining object models and backgrounds of complex composition and high graphical quality, we are able to generate photorealistic images with accurate 3D pose annotations for all objects in all images. Our dataset contains 60k annotated photos of 21 household objects taken from the YCB dataset. For each image, we provide the 3D poses, per-pixel class segmentation, and 2D/3D bounding box coordinates for all objects. To facilitate testing different input modalities, we provide mono and stereo RGB images, along with registered dense depth images. We describe in detail the generation process and statistical analysis of the data.
Read the paper: https://arxiv.org/abs/1804.06534
Light-weight Head Pose Invariant Gaze Tracking
CVPR Workshop on Analysis and Modeling of Faces and Gestures
Rajeev Ranjan, Shalini De Mello, Jan Kautz
Presentation: Friday, June 22 3:10 pm
Abstract: Unconstrained remote gaze tracking using off-the-shelf cameras is a challenging problem. Recently, promising algorithms for appearance-based gaze estimation using convolutional neural networks (CNN) have been proposed. Improving their robustness to various confounding factors including variable head pose, subject identity, illumination and image quality remain open problems. In this work, we study the effect of variable head pose on machine learning regressors trained to estimate gaze direction. We propose a novel branched CNN architecture that improves the robustness of gaze classifiers to variable head pose, without increasing computational cost. We also present various procedures to effectively train our gaze network including transfer learning from the more closely related task of object viewpoint estimation and from a large high-fidelity synthetic gaze dataset, which enable our ten times faster gaze network to achieve competitive accuracy to its current state-of-the-art direct competitor.
Read the paper: https://arxiv.org/abs/1804.08572
Learn more
Join NVIDIA at CVPR 2018 as we showcase our research in deep learning and artificial intelligence. Visit the NVIDIA Booth #807, Hall E to experience our latest deep learning innovations, talk to an NVIDIA deep learning expert, or meet with our hiring team.