Despite the widespread use of convolutional neural networks (CNN), the convolution operations used in standard CNNs have some limitations. To overcome these limitations, Researchers from NVIDIA and University of Massachusetts Amherst, developed a new type of convolutional operations that can dynamically adapt to input images to generate filters specific to the content.
The researchers will present their work at the annual Computer Vision and Pattern Recognition (CVPR) conference in Long Beach, California this week.
“Convolutions are the fundamental building blocks of CNNs,” the researchers wrote in the research paper, “the fact that their weights are spatially shared is one of the main reasons for their widespread use, but it is also a major limitation, as it makes convolutions content-agnostic”.
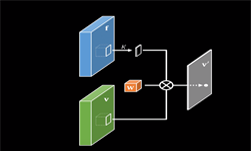
To help improve the efficiency of CNNs, the team proposed a generalization of convolutional operation, Pixel-Adaptive Convolution (PAC), to mitigate the limitation.
The new operation can be described as “a simple modification of standard convolutions,” in which “the filter weights are multiplied with a spatially varying kernel that depends on learnable, local pixel features.”

Despite the simple formulation, PAC can be seen as a generalization of several popular filtering techniques such as standard convolution, bilateral filtering and several pooling operations that are in widespread use in computer vision and computer graphics, and the team demonstrates its powerful potential utility with multiple use cases.
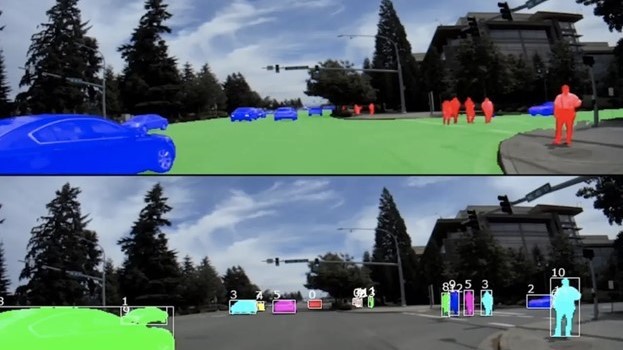
In one of the prominent use cases, the researchers designed a deep neural network to upsample low-resolution signals with the help of high-resolution guidance images.
A couple of example results are shown below, where the task is to upsample low-resolution depth or optical flow signal using high-resolution RGB image as guidance. Because the filters are adaptive to the guidance image, details can be recovered even when completely missing in the low-resolution input. The example below demonstrates the recovery of fine missing details even when upsampling 16 times.

Other demonstrated use cases include deep neural networks for semantic segmentation and efficient inference for Conditional random fields.
The researchers also describe a simple approach to use PAC as a drop-in replacement for standard convolution layers.
The team implemented PAC as a network layer using the cuDNN-accelerated PyTorch deep learning framework, using NVIDIA GPUs at the University of Massachusetts, Amherst and at NVIDIA.
The researchers, which include Hang Su, Varun Jampani, Deqing Sun, Orazio Gallo, Erik Learned-Miller, and Jan Kautz, will present their work on Thursday, June 20, 2019, from 15:20 – 18:00, at CVPR in Long Beach, California.