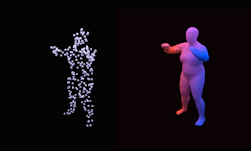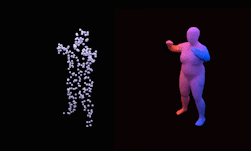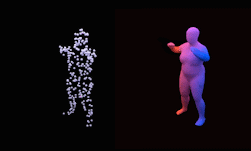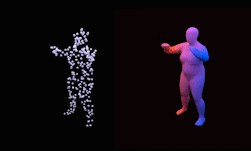By Sandra Skaff
CVPR has become the go to conference for every academic and industry computer vision researcher. The number of paper submissions as well as the number of attendees has been growing at a rate of at least ~20% per year during the last couple of years. Many of our NVAIL partners are at CVPR this week presenting their top-tier research. We feature here a glimpse of the research of three of these partners- Stanford, CASIA (Institute of Automation, Chinese Academy of Sciences), and the Max Planck Institute (MPI).
Stanford
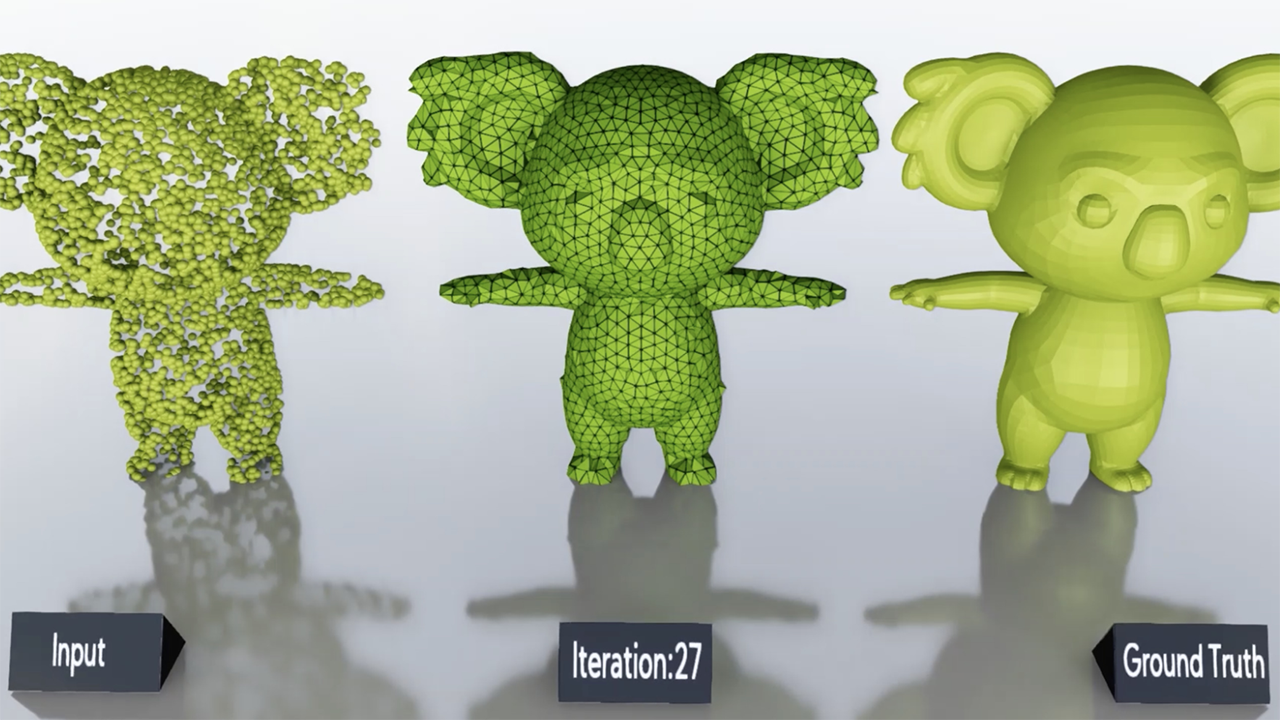
Stanford is presenting a paper on 4D convolutional neural networks (convnets). Why 4D? With the abundance of 3D sensors in robotics and autonomous vehicle applications, continuous streams of 3D images are being collected. Currently, researchers tend to use recurrent neural networks (RNNs) for processing 3D videos and modeling the temporal correlations in them. However the spatial correlations in images make convolutions a great fit for processing these images in one framework which is the 4D convnet.
While 3D convnets have been used by researchers, they have not been very successful since 3D tensors are mostly empty when they come to modeling a 3D space. Sparse representations have been used and adapted to convolutions in the past, but the authors propose the generalized sparse convolution and create the first large-scale 3D/4D network, which they refer to as the Minkowski network. This name is derived from the Minkowski space concept in physics.
The authors proposed the generalized sparse convolution which incorporates all discrete convolutions. Unlike the sparse convolution, it can use a sparse tensor for the convolution kernel, which is critical for high-dimensional convolution and uses non-standard convolution kernels to speed up the inference and regularize the weights. They also proposed an open-source auto-differentiation library for sparse tensors called the Minkowski Engine. The engine consists of the essential libraries to build 3D and 4D convnets, for implementing both the backpropagation and forward pass functions. The Engine was implemented using C++/CUDA with a PyTorch wrapper.
For experiments, the authors chose the semantic segmentation task, and implemented different variants of Minkowski 3D and 4D networks, along with a high-dimensional (7D) conditional random field (CRF) for post-processing segmentation results obtained using the 4D networks. They used multiple standard 3D benchmarks for 3D semantic segmentation: ScanNet, Stanford 3D Indoor Spaces (S3DIS), and RueMonge 2014 (Varcity). Since 4D benchmarks do not exist in the literature, the authors created Synthia 4D using Synthia, which is a synthetic dataset of urban scenes. The 3D Minkowski networks outperformed previous approaches on ScanNet (benchmark results) and S3DIS. The 4D Minkowski networks combined with CRF outperformed previous approaches on the RueMonge 2014 (Varcity) dataset. In addition, the 4D Minkowski network combined with CRF outperformed the 3D Minkowski network on Synthia 4D as expected.
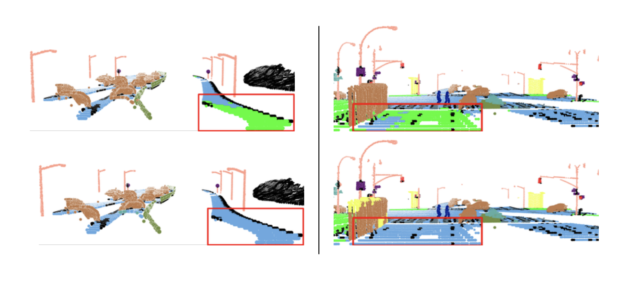
Synthia. A road (blue) far away from the car is often confused as
sidewalks (green) with a 3D network, which persists after temporal
averaging. However, 4D networks accurately captured it.
The authors used the NVIDIA TITAN Xp and TITAN RTX GPUs for training and inference. Training of the MinkowskiUNet42, the Minkowski network with a 42 convolution layers, with a 5m x 5m x 3m room with 2cm resolution input, takes on average 0.987 sec on the Titan Xp and 0.913 sec on a TITAN RTX. Inference takes on average 0.339 sec on the Titan Xp and 0.303 sec on Titan RTX.
The authors hope that their research along with their open source code and results will set a trend in research to adopt a sparse tensor for processing high dimensional data as well as motivate those using 3D convnets to adopt the sparse tensor.
Institute of Automation, Chinese Academy of Sciences (CASIA)
Researchers at CASIA are presenting a novel Attention Enhanced Graph Convolutional LSTM Network (AGC-LSTM) for recognizing human actions from skeleton data. This work was inspired by observing the three characteristics of human motion: human spatial configuration, temporal dynamics, and correlation between spatial configuration and temporal dynamics. Currently most research focuses on the first two characteristics. The authors set out to explore a deep learning based model which is capable of modeling the correlation between spatial and temporal dynamics to push the state of the art on human action recognition.
To the best of the authors’ knowledge, this is the first time graph convolutional LSTMs are used for the task of action recognition. In the proposed architecture, the graph convolution operator within the AGC-LSTM models the spatial information while the LSTM models the temporal dynamics. The attention modeling incorporated into the network is designed to enhance the features of key joints as it can automatically measure the importance of the nodes modeling these joints. Consequently this attention modeling improves spatiotemporal representation.

The proposed AGC-LSTM comprises a joints feature representation (Joint) which is an LSTM encoding of the concatenation of the feature of a joint position and the feature of the difference between two consecutive frames. Several variants of the AGC-LSTM are considered: (1) The network comprising a temporal hierarchical (TH) architecture by stacking 3 AGC-LSTM layers to learn the spatial configuration and temporal dynamics; (2) the network based on parts instead of joints (Part); (3) the hybrid model which combines classification scores from the joints and parts based models (Joint & Part).
The authors demonstrate the performance of their approach for human action classification on two datasets: NTU RGB+D and Northwestern-UCLA. Both datasets contain RGB videos along with depth maps and human skeleton data. AGC-LSTM (Joint) and AGC-LSTM (Part) achieve higher classification accuracies than state of the art approaches on both datasets. Furthermore, AGC-LSTM (Joint & Part) achieves the highest accuracy. The authors also compare different architectures of the proposed network and show that the AGC-LSTM (Joint & Part) provides the highest classification accuracy for human action recognition.
The network was implemented using PyTorch and a single model was parallelized and trained on 2 NVIDIA Titan Xp GPUs. The training takes ~20 hours for the AGC-LSTM (Joint) model, and ~10 hours for the AGC-LSTM (Part) model. Inference is run on a single Titan Xp and takes ~59 msec for a video from the NTU dataset and ~33 msec for a video from the Northwestern-UCLA dataset.
Max Planck Institute (MPI)
Researchers at the Max Planck set out to revisit computer vision from first principles. Since humans are capable of perceiving the world as a set of components or parts which have relationships with another, an artificial agent should be able to do the same. As an example, a robot needs to perceive the parts of an object in order to be able to grasp it.
The goal of the research presented is to find a compact and good object representation which enables effective high-level 3D scene understanding. The most recent trend has been to model objects using 3D cuboids. The authors consider modeling shapes using superquadrics as they are able to represent a more diverse class of shapes such as cylinders, spheres, and cuboids in a single continuous parameter space.
The first contribution of the paper is revisiting the modeling of shapes using superquadrics in the context of deep learning. The second contribution is providing an analytical closed-form solution
to the Chamfer distance function computed between the points on a predicted shape and the points on a target shape. The neural network architecture comprises an encoder and a set of linear layers followed by non-linearities which predict pose, shape, and size of the superquadric surfaces. The training is carried out to minimize the loss function which is the Chamfer distance function mentioned above. An important property of the neural network is that it does not rely on primitive annotations of shapes, and also learns to infer the number of primitives required to represent a shape as well as the correspondence between the primitives and the parts in an unsupervised fashion from unstructured point clouds. Another feature of the network proposed is that it can take many different forms of input, including meshes, point clouds and depth maps.
The authors demonstrate the performance of their approach on two 3D datasets: ShapeNet and SURREAL. They also compare to a previous approach which models cuboids using reinforcement learning. The proposed approach not only provides better shape representations, but also requires less time per training iteration and results in a lower training loss in less iterations than the previous method.

The method is implemented using PyTorch and all experiments are run on an NVIDIA Titan Xp. The training time for a batch size of 32 is ~0.38 sec. This time is based on sampling 1000 points from the target point cloud and 200 points from each primitive for a total of 32 primitives. The inference time for the same setup is ~0.031 sec. The authors also make their implementation available on Github.
MPI is also presenting another paper in which they propose to perform depth fusion in the image domain by successively reprojecting information from neighbouring views to leverage multiview constraints. The authors also create two synthesis multi-view datasets for pretraining and make them available along with their code on this page.
Last but not least, MPI along with NVIDIA and MIT are presenting a paper on competitive collaboration, a framework which facilitates the coordinated training of multiple specialized neural networks to solve complex problems. The idea of this framework was motivated by exploiting geometric constraints in four fundamental vision problems more explicitly as well as segmenting the scene into static and moving regions. The framework allows for jointly learning a model to solve the four problems: depth, camera motion, optical flow and motion segmentation. The model is trained without supervision and achieves state of the art performance. All the models and code are made available on Github.