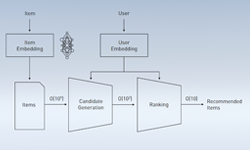
Machine learning workflows require iteration and experimentation. Improvements in performance, particularly speed, provides the opportunity to run additional experiments within a day, week, or month. The ability to increase iteration and experimentation potentially leads to improved models and impactful insights.
Training benchmarks suites from industry consortiums, including MLPerf Training, provide a “fair and useful” benchmark when evaluating performance. These benchmarks help data scientists, machine learning engineers, and researchers decide whether to integrate a technique, package, model, or framework into their workflow.
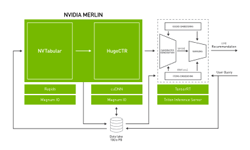
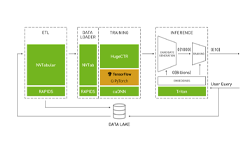
NVIDIA Merlin is the powerhouse behind NVIDIA’s MLPerf .07 submission that establishes NVIDIA as the fastest commercially available solution for recommender system training. Also, the latest update to the NVIDIA Merlin Open Beta includes increased support for Deep Learning Recommender Model (DLRM), a model that enables industry to work more efficiently with production-scale data. NVIDIA’s performance in the industry-supported MLPerf Training benchmark and the latest Merlin Open Beta update reaffirms NVIDIA’s commitment to democratizing large-scale deep learning recommenders for business.
MLPerf Training Benchmarks
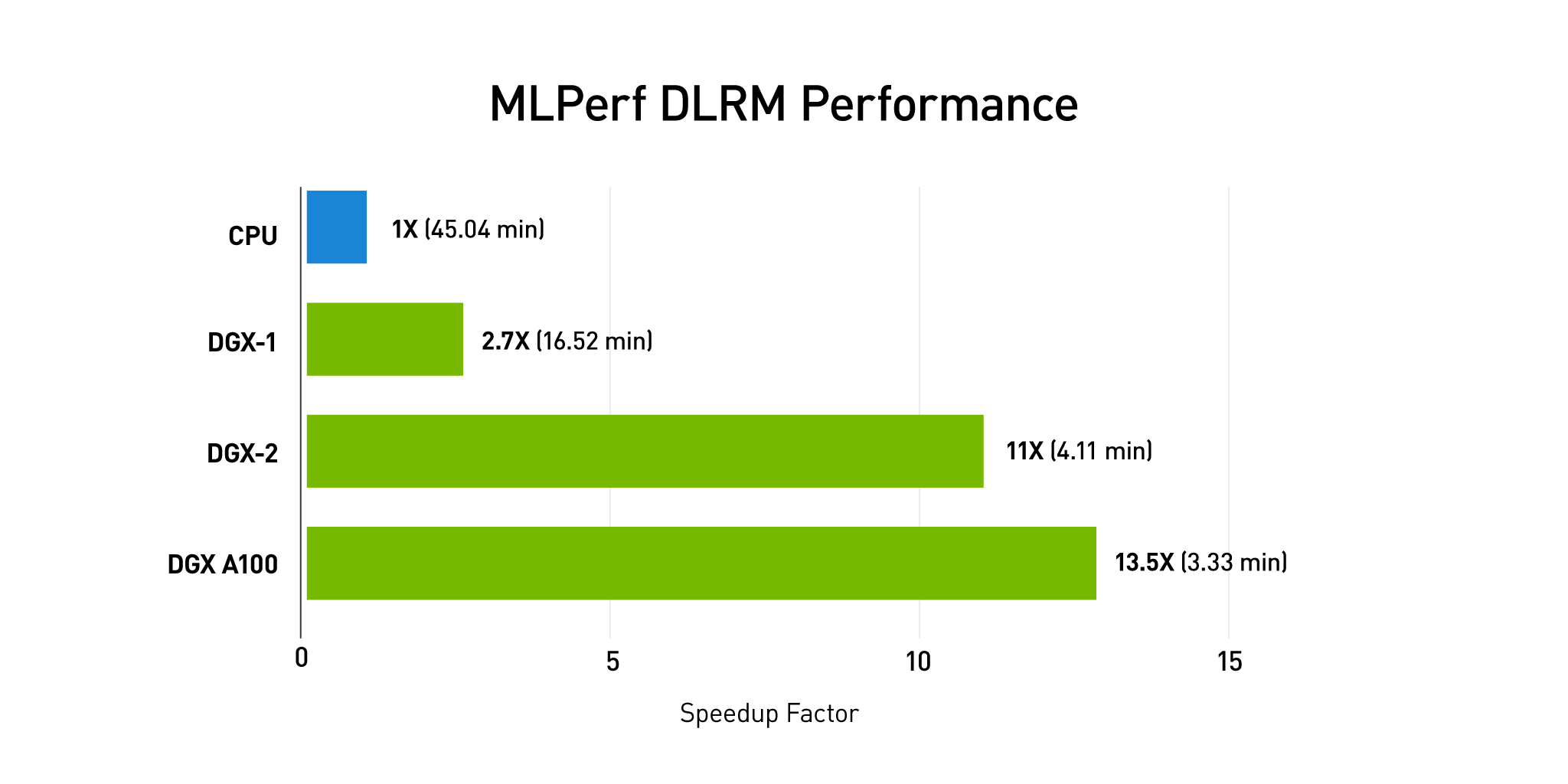
MLPerf Training v0.07 included eight different workloads covering a broad range of use cases, including recommenders. NVIDIA’s full-stack approach based on the new NVIDIA A100 GPU resulted in the fastest commercially available solution for all workloads, including recommender training. According to MLPerf results, NVIDIA Merlin HugeCTR, coupled with a single NVIDIA DGX A100 system, is capable of training a DLRM network on the Criteo 1TB dataset 13.5 times faster than a 4×4 node, 16 CPU cluster, as in Figure 1.

At 3.33 minutes, Merlin HugeCTR on DGX-A100 is the fastest commercially available system on the MLPerf training recommender benchmark.
Next Steps
To reproduce our MLPerf DLRM training performance with Merlin HugeCTR specifically, you can review the sample on github or review the step-by-step technical walkthrough at “Accelerating Recommender Systems Training with NVIDIA Merlin Open Beta“.
Watch the GTC 2020 keynote or join us for our upcoming GTC sessions:
- A Deep Dive into the Merlin Recommendation Framework
- Winning the 2020 RecSys Challenge with Kaggle Grandmasters
- Optimizing AI Systems for Deep Learning Personalization and Recommendation
- Deep Learning at Scale for Personalization Use Cases in E-Commerce and Media Streaming
- Learn How Personalized Marketing is Advancing in Today’s Digital Era
Footnote: MLPerf v0.7 comparison at Max Scale. Max Scale used for NVIDIA A100 and 3rd Gen Intel Xeon Platinum processor. MLPerf ID at Scale: DLRM: 0.7-59, 0.7-17. See www.mlperf.org for more information.