Earlier this year, we talked about performance breakthroughs enabled by two new technologies we developed. Related to data augmentation and tensor parameter interleaving, these technologies enabled a single Tesla V100 GPU to do a ResNet-50 training run in just under 24 hours (1,350 images/second).
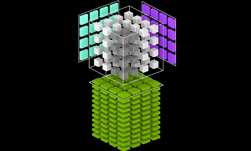
We also discussed how these same technologies enabled a single DGX-1 server node to train ResNet in just over four hours (7,850 images/second). Since then, we put our 16-GPU DGX-2 server to the test, and using these same enabling technologies, DGX-2 finished the training run in 108 minutes (just under two hours)! The run uses 90 epochs, and converges to 75.8% accuracy. Training times used to be measured in days and sometimes even weeks, but this level of speed and accuracy means deep learning researchers can now retrain models multiple times per day if they choose.
A combination of things make this milestone possible, including work done with the MXNet community to implement both our Data Augmentation Library (DALI) as well as our optimizations around tensor parameters. This second technology eliminates data format transpositions by representing every tensor in the ResNet-50 model graph in the optimized format directly, a feature supported by the MXNet framework. Our DALI library moves the data augmentation pipeline stage of training runs from the server CPU onto Tesla GPUs, dramatically accelerating them. Combined with a DGX-2 server capable of 2 petaflops of deep learning compute, and the result is this single-node achievement.

And finally, the newest member of the Tesla product family, the Tesla T4 GPU is arriving in style, posting a new efficiency record for inference. With its small form factor and 70-watt (W) footprint design, T4 is optimized for scale-out servers, and is purpose-built to deliver state-of-the-art Inference in real-time. Powered by 2,560 CUDA Cores and 320 Turing Tensor Cores, Tesla T4 is delivering 56 images/second/watt, more than double its predecessor, the Tesla P4. This achievement is made possible by the addition of INT8 precision running in the Turing Tensor Cores, which brings both performance and efficiency, and a near-zero loss in accuracy.
Tesla T4 is at the heart of the NVIDIA TensorRT Hyperscale Platform, which also includes the TensorRT Inference Server, a containerized microservice that enables applications to use diverse AI models in data center production. This container is freely available from the NVIDIA GPU Cloud container registry. The third member of this platform is the TensorRT 5 optimizer and runtime engine.
Check back often as we continue to bring more performance records here to the Developer News Center.
NVIDIA DGX-2 AI Supercomputer and New Tesla T4 Set Image Recognition Records for Training and Inference
Sep 12, 2018
Discuss (0)

Related resources
- GTC session: Accelerating Autonomous Vehicle Development With High-Performance AI Computing
- GTC session: Global Innovators: Scaling Innovation With NVIDIA AI
- GTC session: Live from GTC: A Look Inside the DGX Architecture
- NGC Containers: Ironyun - ainvr-app
- SDK: DRIVE Constellation
- SDK: MONAI Cloud API