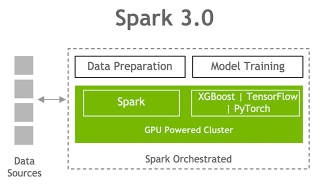
NVIDIA today announced that it is collaborating with the open-source community to bring end-to-end GPU acceleration to Apache Spark 3.0, an analytics engine for big data processing used by more than 500,000 data scientists worldwide.
With the anticipated late spring release of Spark 3.0, data scientists and machine learning engineers will for the first time be able to apply revolutionary GPU acceleration to the ETL (extract, transform and load) data processing workloads widely conducted using SQL database operations.
In another first, AI model training will be able to be processed on the same Spark cluster, instead of running the workloads as separate processes on separate infrastructure. This enables high-performance data analytics across the entire data science pipeline, accelerating tens to thousands of terabytes of data from data lake to model training, without changes to existing code used for Spark applications running on premises and in the cloud.
Building on its strategic AI partnership with NVIDIA, Adobe is one of the first companies working with a preview release of Spark 3.0 running on Databricks. It has achieved a 7x performance improvement and 90 percent cost savings in an initial test, using GPU-accelerated data analytics for product development in Adobe Experience Cloud and supporting features that power digital businesses.
Apache Spark was originally created by the founders of Databricks, whose cloud-based Unified Data Analytics Platform runs on over 1 million virtual machines every day. NVIDIA and Databricks have collaborated to optimize Spark with the RAPIDS™ software suite for Databricks, bringing GPU acceleration to data science and machine learning workloads running on Databricks across healthcare, finance, retail and many other industries.