Researchers from NVIDIA, led by Stan Birchfield and Jonathan Tremblay, developed a first of its kind deep learning-based system that can teach a robot to complete a task by just observing the actions of a human. The method is designed to enhance communication between humans and robots and at the same time further research that will enable people to work alongside robots seamlessly.
“For robots to perform useful tasks in real-world settings, it must be easy to communicate the task to the robot; this includes both the desired result and any hints as to the best means to achieve that result,” the researchers stated in their research paper. “With demonstrations, a user can communicate a task to the robot and provide clues as to how to best perform the task.”
Using NVIDIA TITAN X GPUs, the researchers trained a sequence of neural networks to perform duties associated with perception, program generation, and program execution. As a result, the robot was able to learn a task from a single demonstration in the real world.
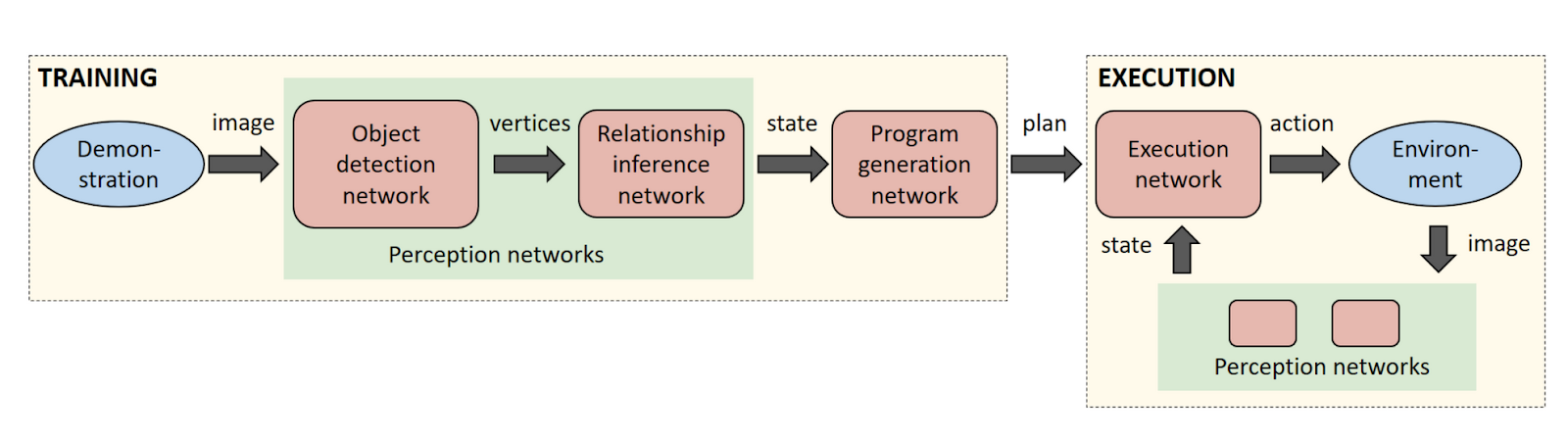
Once the robot sees a task, it generates a human-readable description of the steps necessary to re-perform the task. The description allows the user to quickly identify and correct any issues with the robot’s interpretation of the human demonstration before execution on the real robot.
The key to achieving this capability is leveraging the power of synthetic data to train the neural networks. Current approaches to training neural networks require large amounts of labeled training data, which is a serious bottleneck in these systems. With synthetic data generation, an almost infinite amount of labeled training data can be produced with very little effort.
This is also the first time an image-centric domain randomization approach has been used on a robot. Domain randomization is a technique to produce synthetic data with large amounts of diversity, which then fools the perception network into seeing the real-world data as simply another variation of its training data. The researchers chose to process the data in an image-centric manner to ensure that the networks are not dependent on the camera or environment.
“The perception network as described applies to any rigid real-world object that can be reasonably approximated by its 3D bounding cuboid,” the researchers said. “Despite never observing a real image during training, the perception network reliably detects the bounding cuboids of objects in real images, even under severe occlusions.”
For their demonstration, the team trained object detectors on several colored blocks and a toy car. The system was taught the physical relationship of blocks, whether they are stacked on top of one another or placed next to each other.
In the video above, the human operator shows a pair of stacks of cubes to the robot. The system then infers an appropriate program and correctly places the cubes in the correct order. Because it takes the current state of the world into account during execution, the system is able to recover from mistakes in real time.
The researchers will present their research paper and work at the International Conference on Robotics and Automation (ICRA), in Brisbane, Australia this week.
The team says they will continue to explore the use of synthetic training data for robotics manipulation to extend the capabilities of their method to additional scenarios.
Read the research paper and learn more about NVIDIA’s research at ICRA
Related resources
- GTC session: Deploying AI in Real-World Robots
- GTC session: Empowering Collaborative Robots: The Future of AI Vision With Digital Twins
- GTC session: Using Omniverse to Generate First-Person Experiential Data for Humanoid Robots
- SDK: Isaac SDK
- SDK: Isaac Sim
- Webinar: Isaac Developer Meetup #2 - Build AI-Powered Robots with NVIDIA Isaac Replicator and NVIDIA TAO