NVIDIA released TensorRT 4 with new features to accelerate inference of neural machine translation (NMT) applications on GPUs. Neural machine translation offers AI-based text translation for large number of consumer applications, including web sites, road signs, generating subtitles in foreign languages, and more.
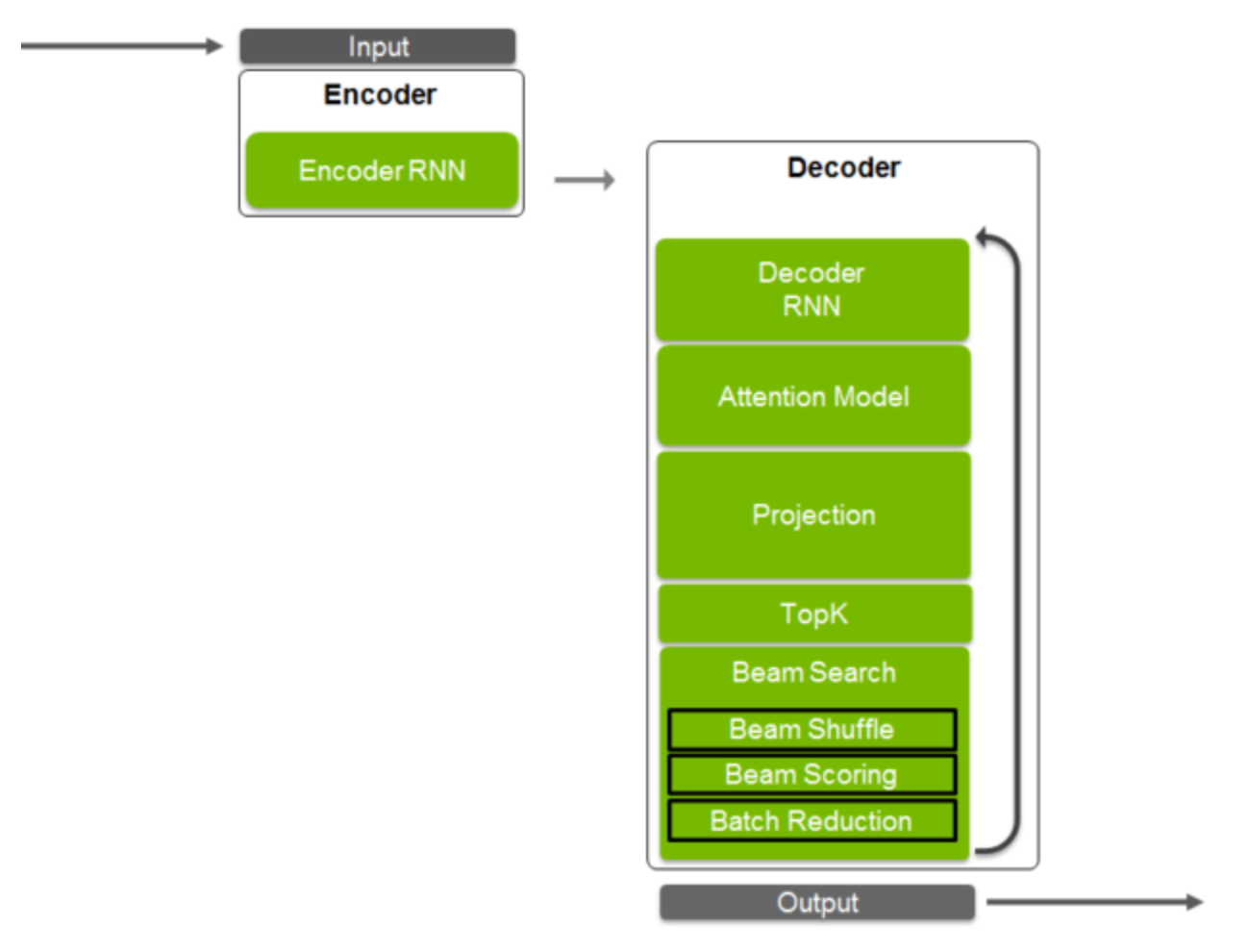
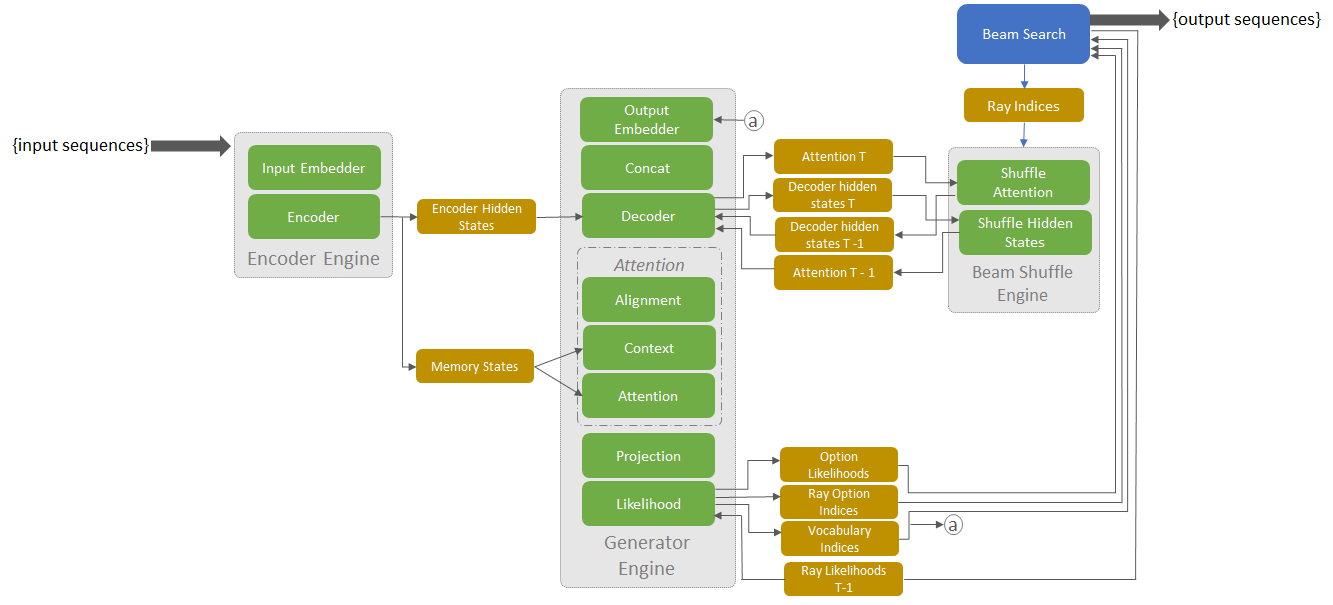
The new TensorRT 4 release brings support for new RNN layers such as Batch MatrixMultiply, Constant, Gather, RaggedSoftMax, Reduce, RNNv2, and TopK. These layers allow application developers to accelerate the most compute intensive portions of an NMT model easily with TensorRT.
In terms of performance, when beam search was tested on the data-writer-benchmark component, the system performed 170 times faster than a CPU-only during inference for batch=1 and over 100 times faster for batch size = 64.
TensorRT, NVIDIA’s programmable inference accelerator, helps optimize and generate runtime engines for deploying deep learning inference apps to production environments. The GNMT model performed inference 60x faster using TensorRT on Tesla V100 GPUs as compared to CPU-only platforms.
Neural Machine Translation Now Available with TensorRT
Jul 18, 2018
Discuss (0)
Related resources
- GTC session: Optimizing and Scaling LLMs With TensorRT-LLM for Text Generation
- GTC session: Optimize Generative AI inference with Quantization in TensorRT-LLM and TensorRT
- GTC session: Optimizing Inference Performance and Incorporating New LLM Features in Desktops and Workstations
- SDK: TensorFlow-TensorRT
- SDK: TensorRT-ONNX Runtime
- SDK: TensorRT - MXNet