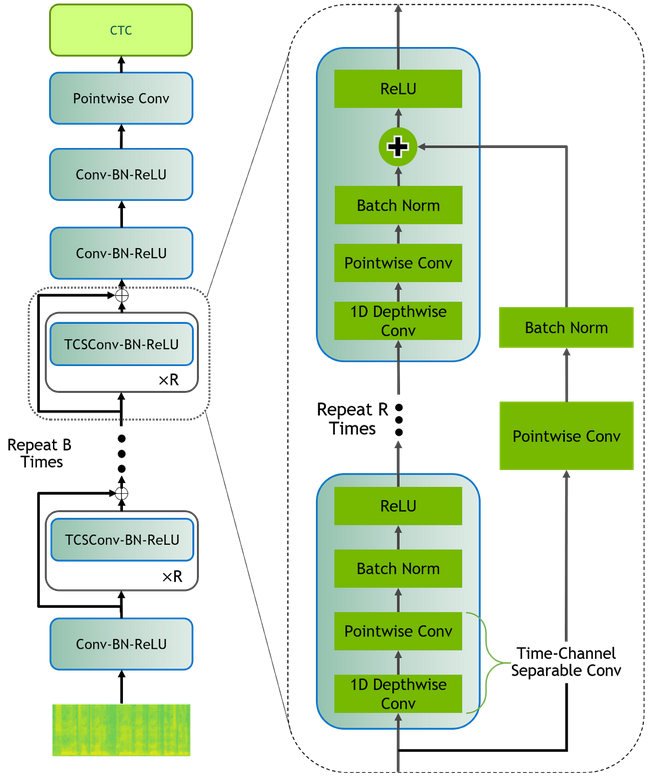
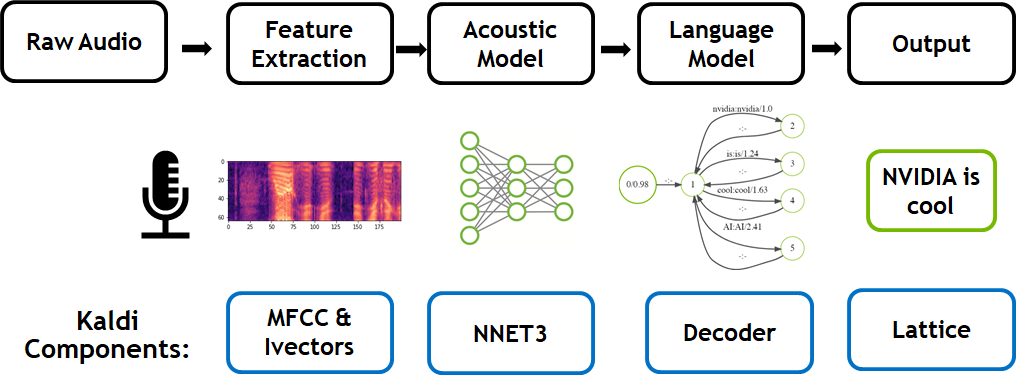
Researchers at Microsoft announced they reached a 5.1% error rate which is a new milestone in reaching human parity for recognizing words in a conversation as well as professional human transcribers.
They improved the accuracy of their system from last year on the Switchboard conversational speech recognition task. The benchmarking task is a corpus of recorded telephone conversations that the speech research community has used for more than 20 years to benchmark speech recognition systems. The task involves transcribing conversations between strangers discussing topics such as sports and politics.
“We reduced our error rate by about 12 percent compared to last year’s accuracy level, using a series of improvements to our neural net-based acoustic and language models. We introduced an additional CNN-BLSTM (convolutional neural network combined with bidirectional long-short-term memory) model for improved acoustic modeling,” mentioned Xuedong Huang, Technical Fellow at Microsoft. “Additionally, our approach to combine predictions from multiple acoustic models now does so at both the frame/senone and word levels.”
Using GPUs on Microsoft Azure and the cuDNN-accelerated CNTK deep learning framework, the researchers strengthened the recognizer’s language model by using the entire history of a dialog session to predict what is likely to come next, effectively allowing the model to adapt to the topic and local context of a conversation.
“(Azure GPUs) helped to improve the effectiveness and speed by which we could train our models and test new ideas,” said Huang.
![]()
The team acknowledges that while achieving a 5.1 percent word error rate on the Switchboard speech recognition task is a significant achievement, the speech research community still has many challenges to address, such as achieving human levels of recognition in noisy environments with distant microphones, in recognizing accented speech, or speaking styles and languages for which only limited training data is available.
Read more >
Related resources
- GTC session: Live from GTC: A Conversation with Microsoft
- GTC session: Human-Like AI Voices: Exploring the Evolution of Voice Technology
- GTC session: Adapting Conformer-Based ASR Models for Conversations Over the Phone
- NGC Containers: Autovox Hindi ASR
- NGC Containers: MATLAB
- Webinar: How Telcos Transform Customer Experiences with Conversational AI