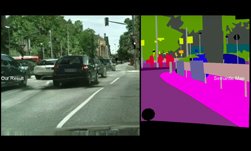
Researchers at Microsoft and the University of Montreal recently developed a deep learning system that can generate realistic images from written dialogue.
The research, according to Microsoft, is the first known project that uses dialogue, instead of captions, to generate pictures.
The researchers used a method called generative adversarial networks (GANs). Previous work in this field has focused on generating low-resolution images from text captions. However, the captions might not be informative enough to produce a realistic image from the text, the researchers said.
Using NVIDIA GPUs and the cuDNN-accelerated PyTorch deep learning framework, the team trained their system on 80,000 images from the Microsoft Commons Objects in Context (MS COCO) dataset. The dataset includes categories of objects such as person and accessoy, animal, and vehicle. The team tested their results on a separate dataset of 40,000 images.

To develop the model, the developers took inspiration from sketch artists who draw sketches while conversing with a person who describes a scene or a person.
“Sketch artists typically have a back-and-forth conversation with witnesses when they have to draw a person’s sketch, where the artist asks for more details and draws the sketch while the witnesses provide requested details and feedback on the current state of the sketch.” the researchers wrote in their research paper.

The new method has the potential to revolutionize the video game and image editing industries, as well as accessibility, the researchers said. However, the team concedes their model isn’t perfect and can sometimes generate unrecognizable objects.
For future work, the team says they will focus on collecting a dataset that mirrors the sketch process, in which an artist would make several changes to an image as the conversation progresses.
Read more>