Previously known as CNTK, the Microsoft Cognitive Toolkit version 2.0 allows developers to create, train, and evaluate their own neural networks that can scale across multiple GPUs and multiple machines on massive data sets.
The open-source toolkit, available on GitHub, offers hundreds of new features, performance improvements and fixes that have been added since the beta version of CNTK. New features announced today include the support for Keras, a popular open-source neural network library, and new tools that compress trained models to run in real-time.
To accelerate training capabilities, the toolkit ingrates the latest version of the NVIDIA Deep Learning SDK and optimized for Volta, the most powerful GPU architecture the world has ever seen.
CNTK has been used worldwide by companies and organizations for their AI efforts.
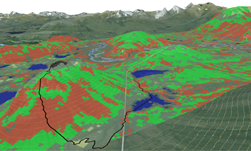
Maryland-based Chesapeake Conservancy is using the toolkit to develop up-to-date one-meter resolution land cover datasets which can be used to prioritize restoration and protection initiatives throughout the Chesapeake Bay, which spans approximately 64,000 square miles in six states and Washington, D.C. Their new datasets have 900 times the information of existing 30-meter resolution datasets, and would require months of data entry and image processing to create – with the help of AI and the toolkit, it now takes them a fraction of the time.
“Originally, people handwrote their own mathematical functions and created their own neural networks with their own private code and figured out how to feed it with data all by themselves,” said Chris Basoglu, a partner engineering manager at Microsoft and key developer of CNTK. “But now the data is so large, the algorithms are so complex and optimization across multiple GPUs, CPUs and machines is so prohibitive that it is not feasible for someone to write their own. They need tools.”
Read more >