To enhance the capability of text-to-speech and automatic speech recognition algorithms, Microsoft researchers developed a deep learning model that uses unsupervised learning, an approach not commonly used in this field, to improve the accuracy of the two speech tasks.
By using the Transformer model, which is based on a sequence-to-sequence architecture, the team achieved a 99.84% accuracy in terms of word level intelligible rate for text-to-speech and 11.7% PER for automatic speech recognition, outperforming three other baseline models.
“Recently, Transformer has achieved great success and outperformed RNN or CNN based models in many NLP tasks such as neural machine translation and language understanding,” the researchers stated in their paper. “Transformer mainly adopts the self-attention mechanism to model interactions between any two elements in the sequence and is more efficient for sequence modeling than RNN and CNN,” the researchers explained in their paper, Almost Unsupervised Text to Speech and Automatic Speech Recognition.
Using data from the LJSpeech dataset, which contains 13,100 English audio clips and the corresponding transcripts, the team randomly chose 200 audio clips and the corresponding transcripts from the training set as the paired data for training. With 4 NVIDIA P100 GPUs, the team trained the transformer model to reconstruct speech and text sequences.
Specifically, the team uses a denoising auto-encoder to reconstruct corrupt speech and text in an encoder-decoder framework, the team explained. The end result can take speech or text as input or output.
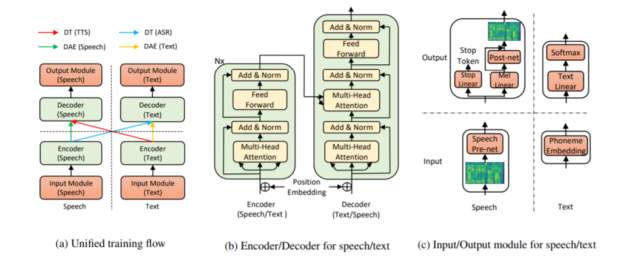
The overall model structure for TTS and ASR. Figure (a): The unified training flow of our method, which consists of a denoising auto-encoder (DAE) of speech and text, and dual transformation (DT) of TTS and ASR, both with bidirectional sequence modeling. Figure (b): The speech and text encoder and decoder based on Transformer. Figure (c): The input and output module for speech and text.
“Our method is carefully designed for the low-resource or almost unsupervised setting with several key components including denoising auto-encoder, dual transformation, bidirectional sequence modeling for TTS and ASR,” the researchers stated in their paper. “Some components such as dual transformation are in spirit of the backtranslation in neural machine translation. However, different from unsupervised translation where the input and output sequence are in the same domain, speech and text are in different domains and more challenging than translation. We demonstrate in our experiments that our designed components are necessary to develop the capability of speech and text transformation with few paired data.”
The researchers have published several examples of the work on their site and will soon publish their code to GitHub.
Results from the algorithm: The forms of printed letters should be beautiful and that their arrangement on the page should be reasonable and a help to the shapeliness of the letters themselves. Source: Microsoft
The research will be presented at the International Conference on Machine Learning, in Long Beach California later this year.