
Meet the Researcher is a series in which we spotlight different researchers in academia who are using GPUs to accelerate their work. This week, we spotlight Raphaël Frank, Senior Research Scientist at the SnT Research Center of the University of Luxembourg. The research featured in this article is part of the project of François Robinet , PhD Student at the University of Luxembourg.

Raphael received his Ph.D. in Computer Science from the University of Luxembourg, in 2010. He is part of the Sedan research group and member of the Technology Transfer Office (TTO), since 2017. He is also the founder and Head of the 360Lab, the first thematic research laboratory at SnT, focusing on Connected and Automated Mobility. His research expertise includes distributed systems and machine learning for mobility applications.
What are your research areas of focus?
My research interests are in autonomous systems, with a particular focus on perception through computer vision. This includes applications in object detection, lane following and depth estimation.
What motivated you to pursue this research area of focus?
Automation is the essence of computer science, and a good chunk of what makes it appealing to me. Now that robots are starting to leave the constrained environments of labs and factory floors, it is more important than ever to ensure that their use is safe. It is also more challenging: although much progress has occurred over the last decade, there is still a lot of exciting research to be done before we can fully trust our autonomous robotic friends.
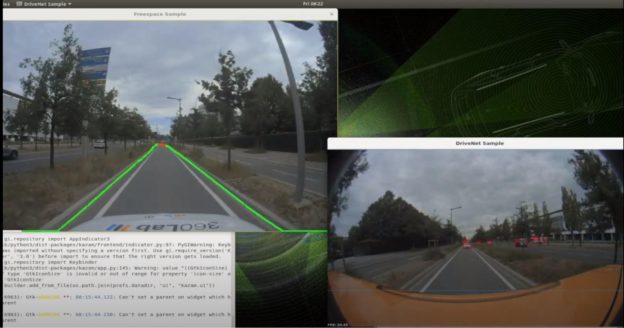
Tell us about your current research projects.
I am currently working on dense monocular depth estimation, which consists in assigning a depth value to every pixel of an image or video. Estimating such distance is of great importance for autonomous systems, especially when alternative sensors like LiDARs are typically expensive and only yield sparse depth maps. There are also interesting applications in augmented reality, where depth information can be used to realistically blend virtual assets in a real scene.
What problems or challenges does your research address?
In recent years, self-supervised techniques have emerged to attempt to learn from raw monocular videos, with results that are slowly approaching those of fully supervised methods. Self-supervised methods rely on joint depth and camera ego-motion estimation, and use consistency photometric losses derived from the pin-hole camera model to provide a learning signal. My research builds on these approaches to improve performance so that they can match supervised methods, while being more robustly applicable to the wide variety of scenarios encountered by autonomous robots in the wild. In order to improve learning, we alter the architecture by embedding real-world constraints directly into the network.
What is the (expected) impact of your work on the field/community/world?
Monocular depth estimation has historically been approached using fully-supervised methods, which would generally require collecting and annotating new data before fine-tuning. Self-supervision allows us to leverage large publicly available raw video datasets, and makes data collection cheaper when it remains necessary. Our contribution is adding geometrical and motion constraints in the hope of improving model robustness. Baking such inductive bias directly into the architecture has previously shown great results, as attested by the translational invariance brought about by convolutional networks.
How have you used NVIDIA technology either in your current or previous research?
We rely on NVIDIA GPUs hosted inside the High Performance Computing platform of the University for training deep learning models and running the heavy experiments and parameter tuning required for self-supervised learning. The research vehicle of the 360Lab is also equipped with an NVIDIA DRIVE AGX platform, which is used for both data collection and inference experiments. Regarding software, we explicitly rely on DALI and NCCL for distributed training, but we also leverage CuDNN through higher-level frameworks like Tensorflow or PyTorch. On the research side, we are also fortunate to collaborate with researchers from the NVIDIA AI Technology Center (NVAITC) Luxembourg.
Did you achieve any breakthroughs in that research or any interesting results you can share?
Our self-supervised depth estimation results are not yet ready for publication, but I am hoping that constraining the hypothesis space in ways that make sense to humans will have a positive impact on generalization. In earlier work, we proposed to similarly constrain learning by leveraging visualization at training time to force an end-to-end car steering model to look for relevant cues.
Can you describe in greater detail the performance cards and systems you used?
For now, our experiments have run using two Tesla K80 independently (running different experiments in parallel). We haven’t tried using a CPU only platform, but training that kind of model on CPU is basically impossible.
We are using a subset of the KITTI dataset, which is commonly accepted as a benchmark in this line of research. Since the dataset is relatively small, the initial experiments were done on a single GPU, using a small batch size. We are also collecting our own data using the experimental vehicle of the 360Lab, which will allow us to better assess the transfer learning capabilities of our models.
Can you expand on the real-time aspects of the research?
In many scenarios, running in real-time means reaching something like 30 FPS. However, for automotive applications, the path planning and control loops typically run much faster than perception, which means that they are operating on stale data, and can always benefit from higher perception rates.
We plan on studying the applicability of this research for autonomous driving in real time scenarios, but innovations in model architecture have been our focus until now. The architecture of course has an impact on runtime, but prior art has shown that using decently sized networks as the backbone of the architecture can yield good results.
What’s next for your research?
Our research team will keep working on ways to improve the performance and robustness of camera-based perception systems that use less annotations.
Earlier work that we are aware of has relied on architectures that were pretrained on ImageNet. These have been shown to yield better performance than training from scratch for a comparable amount of time. It would be interesting to see if we can beat these results when constraining the architecture and letting the training run from scratch for a longer time. The team will grow soon and we have many exciting projects for prospective PhD students!
Any advice for new researchers?
I would suggest keeping a breadth of interests in your field and fostering collaboration. Interacting with your peers at conferences, seminars and short talks are all great ways of gaining both a deeper understanding and new perspectives!









