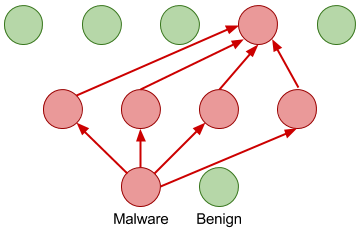
The detection of malicious software (malware) is an increasingly important cyber security problem for all of society. Single incidences of malware can cause millions of dollars in damage. The current generation of anti-virus and malware detection products typically use a signature-based approach, where a set of manually crafted rules attempt to identify different groups of known malware types. These rules are generally specific and brittle, and usually unable to recognize new malware even if it uses the same functionality.
This approach is insufficient because most environments have unique binaries that will have never been seen before and millions of new malware samples are found every day. The need to develop techniques that can adapt to the rapidly changing malware ecosystem is seemingly a perfect fit for machine learning. Indeed, a number of startups and established cyber-security companies have started building machine learning based systems. These companies typically spend considerable effort in feature engineering and analysis to build high quality systems. But what if we could build an anti-virus system without any feature engineering? That could allow the same system to detect malware across a variety of operating systems and hardware. A new NVIDIA Developer blog post demonstrates a significant step towards this goal made by research completed by NVIDIA Applied Deep Learning Research in collaboration the Laboratory for Physical Sciences, Booz Allen Hamilton and the University of Maryland Baltimore County.
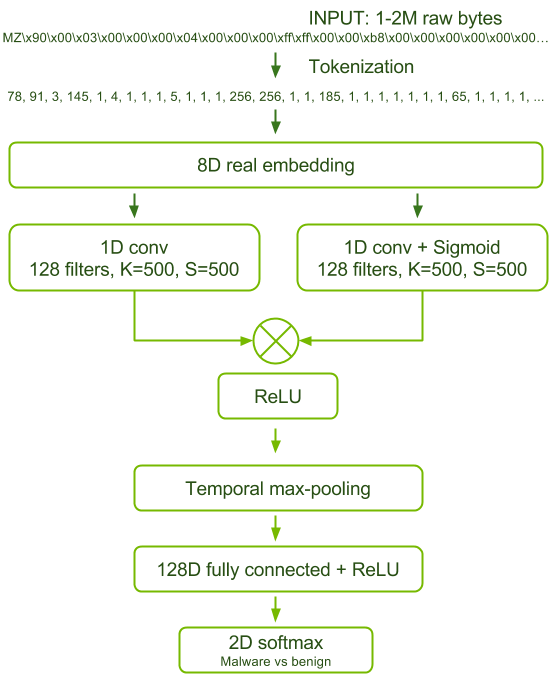
The paper introduces an artificial neural network trained to differentiate between benign and malicious Windows executable files with only the raw byte sequence of the executable as input. This approach has several practical advantages:
- No hand-crafted features or knowledge of the compiler used are required. This means the trained model is generalizable and robust to natural variations in malware.
- The computational complexity is linearly dependent on the sequence length (binary size), which means inference is fast and scalable to very large files.
- Important sub-regions of the binary can be identified for forensic analysis.
- This approach is also adaptable to new file formats, compilers and instruction set architectures—all it needs is training data.