By CJ Newburn, Principal Engineer and HPC Architect, NVIDIA, and Adam Thompson, Senior Solutions Architect, NVIDIA.
At GTC 2019 in Silicon Valley, NVIDIA engineers will present a proof of concept designed to help hardware, systems, applications, and framework developers accelerate their work. In this blog, we describe the current limitations when performing transfers between storage and GPU memory and how the process can be streamlined. For suitable applications, this technology can increase bandwidth, reduce latency, and ease programmability.
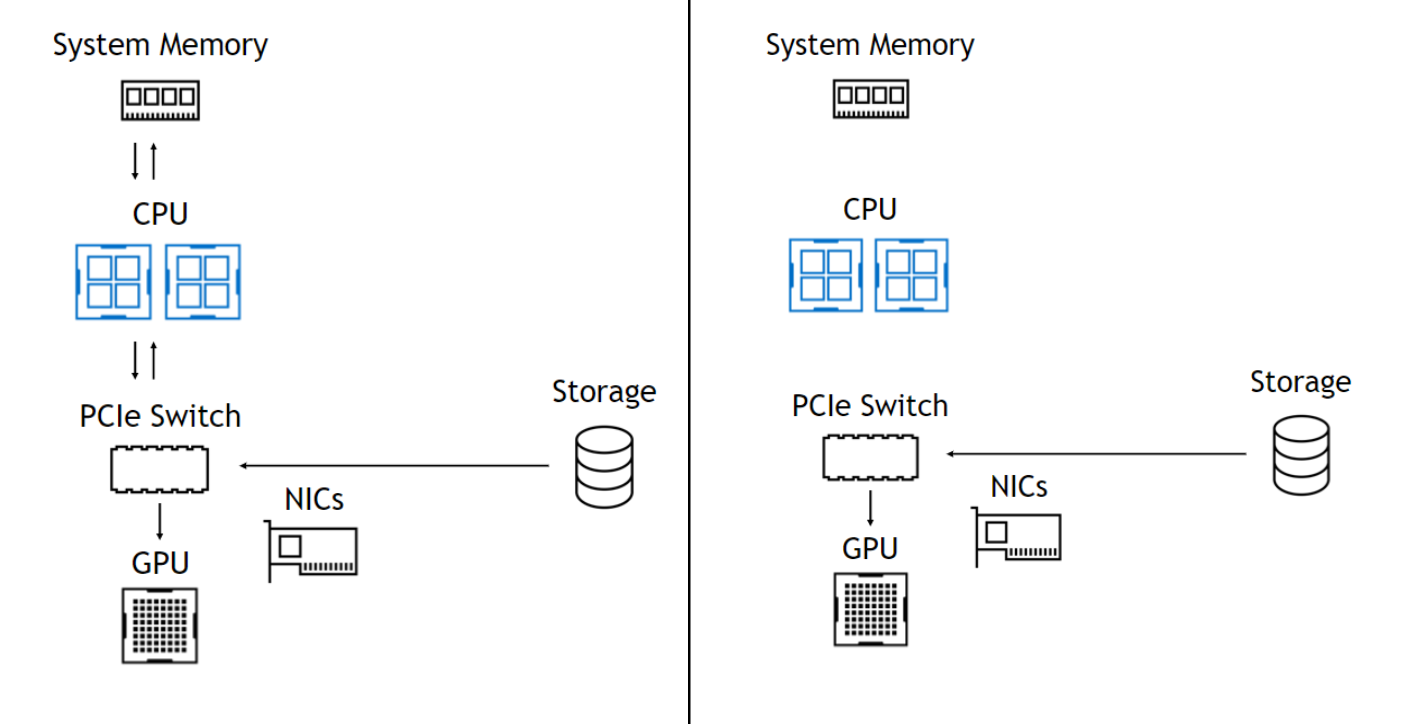
The NVIDIA DGX-2 appliance is a computing behemoth. Featuring 16 Tesla V100 GPUs, each with 32GB of HBM2 memory connected via NVLink- and NVSwitch-based topology, aggregate internal memory bandwidth peaks at 14.4TB/sec. To put 14.4TB into perspective, if a single HD movie is 10GB, the DGX-2 screams through 1,440 movies per second.
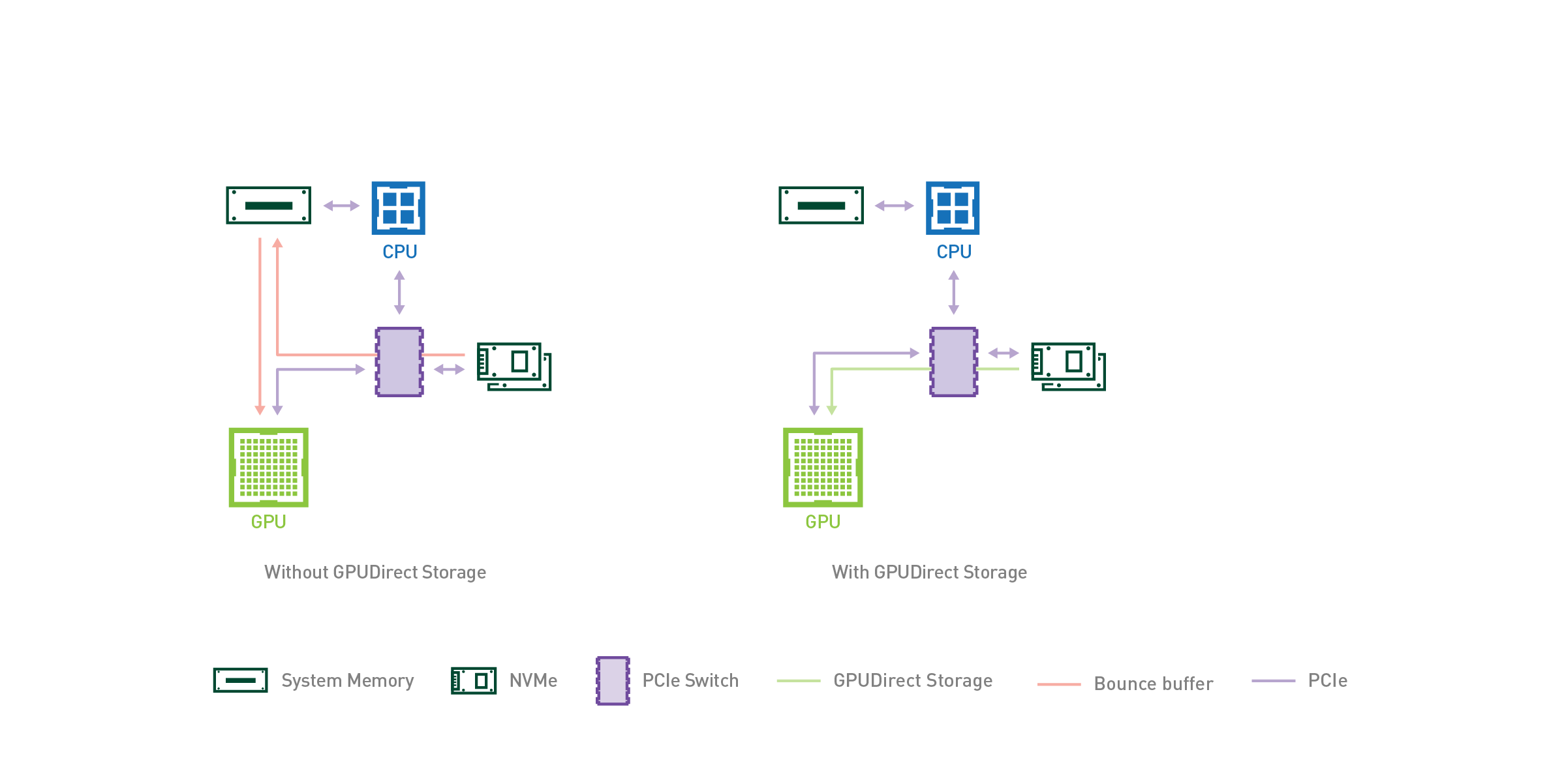
Keeping the data-hungry GPUs fed over PCIe from data sets that don’t fit in a half terabyte of memory, or even in 16 NVMe drives within the appliance enclosure, poses an increasing challenge. As applications are optimized to shift more computation from CPUs to GPUs, GPU memory is becoming the first or last stop before storage. Over time, performance tuning tends to reduce computational latencies, making storage I/O more of a bottleneck. Naturally, the optimization of direct transfers between storage and GPU memory becomes a primary target for relieving this bottleneck. At GTC’19, NVIDIA is sharing results from initial technology investigations into streamlining such transfers to avoid using a bounce buffer in system memory and to elide the CPU altogether, thereby increasing bandwidth, reducing latency, and easing programmability.

Figure: The standard path between GPU memory and NVMe drives uses a bounce buffer in system memory that hangs off of the CPU. The direct data path gets higher bandwidth by eliding the CPU altogether. Direct data paths are possible to storage reached via PCIe (upper right), a RAID card (HBA, lower right), or NVMe-OF (HCA, over fabric, lower left).
At the conference, come join us at Connect with the Experts session CE9141, Thursday, March 21 from 11am-12pm in Hall 3, Pod C, on the Concourse Level. We’ll explain current limitations and bottlenecks, provide technical details on how we’ve overcome them, and share compelling initial performance results. In one example, we demonstrate between a 1.5x and 8x speedup by using a direct data path between NVMe in the enclosure and GPU memory for the cuDF GPU Data Frame that’s part of the RAPIDS open-source software project. Our results are based on a proof of concept, not a shipping product. We invite potential hardware, systems, applications, and framework developers to check out this technology and join us in moving it toward production.
This technology is relevant for platforms of both today and tomorrow, from NVIDIA and our OEMs. We’ll show results using NVMe storage reached via PCIe within an enclosure, storage reached via a RAID card, and storage outside the enclosure, reached with NVMe-oF. We are delighted to have early collaborations with Micron for NVMe storage, MicroSemi for switches and storage controllers, Mellanox for networking, E8 Storage for NVMe-oF solutions that may be added to in-enclosure storage, and HPE for systems and RAID cards. Watch for future blog postings and booth talks from these fellow travelers regarding their early participation in this technology development.
E8 Storage
“Together with NVIDIA, we were able to demonstrate an external, scalable and composable storage solution that delivers bandwidth and latency performance virtually indistinguishable from the NVMe SSD storage within the server itself. Our existing and forthcoming portfolio of appliances and SDS packages are designed to deliver an invaluable complementary upgrade to existing storage solutions for AI/ML systems.” Zivan Ori, CEO and Co-founder of E8 Storage
HPE
“As we strive to advance the customer’s experience and competitive edge, HPE is collaborating with technology leaders like NVIDIA to deliver accelerated computing technologies.” Bill Mannel, VP and GM of HPC and AI, Hewlett Packard Enterprise
Mellanox
As GPU applications require massive amounts of data, our end to end 100Gb/s EDR and 200Gb/s HDR InfiniBand products combined with our leadership in NVMe over Fabrics to NVIDIA GPUs are the perfect solution.” Rob Davis, Vice President of Storage Technology at Mellanox Technologies
Micron
“Micron has succeeded in improving system performance by architecting innovative ways to connect NVIDIA GPUs and fast storage.” Currie Munce, VP Storage Solutions Architecture, Micron
MicroSemi
“Microsemi is pleased to contribute to NVIDIA’s exploration of GPU direct transfers to storage assets in computationally intensive systems like the DGX-2. Based on results to date it is clear that our Switchtec advanced PCIe Gen 4 fabric switches combined with our latest PCIe Gen 4 tri-mode RAID controllers will enable much higher bandwidth data transfers between the NVIDIA GPUs and drives and with much lower latency, even when spanning PCIe domains.” Andrew Dieckmann, VP of Marketing, Data Center Solutions, Microsemi, a Microchip Company
About the Authors

Chris J. Newburn (CJ) is the Principal Architect in NVIDIA Compute Software leading HPC strategy and driving the SW product roadmap, with a special focus on systems and programming models for scale. He has contributed to a combination of hardware and software technologies over the last twenty years and has over 80 patents. He is a community builder with a passion for extending the core capabilities of hardware and software platforms from HPC into AI, data science and visualization. He wrote a binary-optimizing, multi-grained, parallelizing compiler as part of his Ph.D. at Carnegie Mellon University. Before grad school, in the 80s, he did stints at a couple of start-ups, working on a voice recognizer and a VLIW supercomputer.

Adam Thompson is a Senior Solutions Architect at NVIDIA. With a background in signal processing, he has spent his career participating in and leading programs focused on deep learning for radio frequency classification, data compression, high performance computing, and managing and designing applications targeting big data frameworks. His research interests include deep learning, high performance computing, systems engineering, cloud architecture/integration, and statistical signal processing. He holds a Masters degree in Electrical & Computer Engineering from Georgia Tech and a Bachelors from Clemson University.