Researchers from NVIDIA, led by Ting-Chun Wang, have developed a new deep learning-based system that can generate photorealistic images from high-level labels, and at the same time create a virtual environment that allows the user to modify a scene interactively. The researchers, Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro will present their work at the annual Computer Vision and Pattern Recognition Conference in Salt Lake City, Utah this week.
The method, which uses a conditional generative adversarial network (GAN), has the potential to revolutionize how visual algorithms, including those for medical imaging, are trained.
“Conditional GANs have enabled a variety of applications, but the results are often limited to low-resolution and still far from realistic. In this work, we generate 2048×1024 visually appealing results with a novel adversarial loss, as well as new multi-scale generator and discriminator architectures,” the researchers stated in their paper.
Using NVIDIA Quadro GPUs and the cuDNN-accelerated PyTorch deep learning framework, the team trained their neural network on several datasets comprised of thousands of images.
For inference, the team uses NVIDIA GeForce GTX 1080 Ti GPUs.
The neural network is based on the pix2pix system, a conditional GAN framework for image-to-image translation.
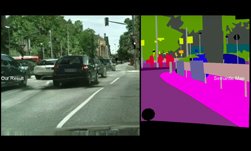
As shown in the video above, the researchers demonstrate their approach by showing how the neural network performs when a user attempts to modify parts of a scene on a European street and a human face. The interactive algorithm can quickly modify facial features such as eye shape, skin tone, adding or removing facial hair, and more. In the street scene, the neural network is able to modify the car’s color, shape, and position on the road.
The two main contributions of the research are the use of instance-level semantic label maps and the ability to generate diverse results given the same input label. For example, instance-level semantic label maps contain a unique ID for each individual object in an image. “This enables flexible object manipulations, such as adding/removing objects and changing object types,” the researchers said. “With the instance map, separating these objects becomes an easier task.”
The neural network can also generate diverse results given the same input label map. “This allows the user to edit the objects, interactively. The image-to-image synthesis pipeline can be extended to produce diverse outputs, and enable interactive image manipulation given appropriate training input-output pairs. Without ever been told what a “texture” is, our model learns to stylize different objects, which may be generalized to other datasets as well.”
The researchers say their method can potentially be used for applications that require high-resolution images but lack pre-trained neural networks.
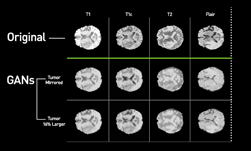
“We believe these contributions broaden the area of image synthesis and can be applied to many other related research fields,” including medical imaging and biology, the team said.
Generating and Editing High-Resolution Synthetic Images with GANs
Jun 19, 2018
Discuss (0)
Related resources
- DLI course: Data Augmentation and Segmentation with Generative Networks for Medical Imaging
- GTC session: Efficient Geometry-Aware 3D Generative Adversarial Networks
- GTC session: Performant Object Recognition Model Trained with On-Demand Synthetic Data
- GTC session: AI for Learning Photorealistic 3D Digital Humans from In-the-Wild Data
- SDK: Omniverse Replicator
- Webinar: Isaac Developer Meetup #2 - Build AI-Powered Robots with NVIDIA Isaac Replicator and NVIDIA TAO