Autonomous driving demands safety, and a high-performance computing solution to process sensor data with extreme accuracy. Researchers and developers creating deep neural networks (DNNs) for self driving must optimize their networks to ensure low-latency inference and energy efficiency. Thanks to a new Python API in NVIDIA TensorRT, this process just became easier.
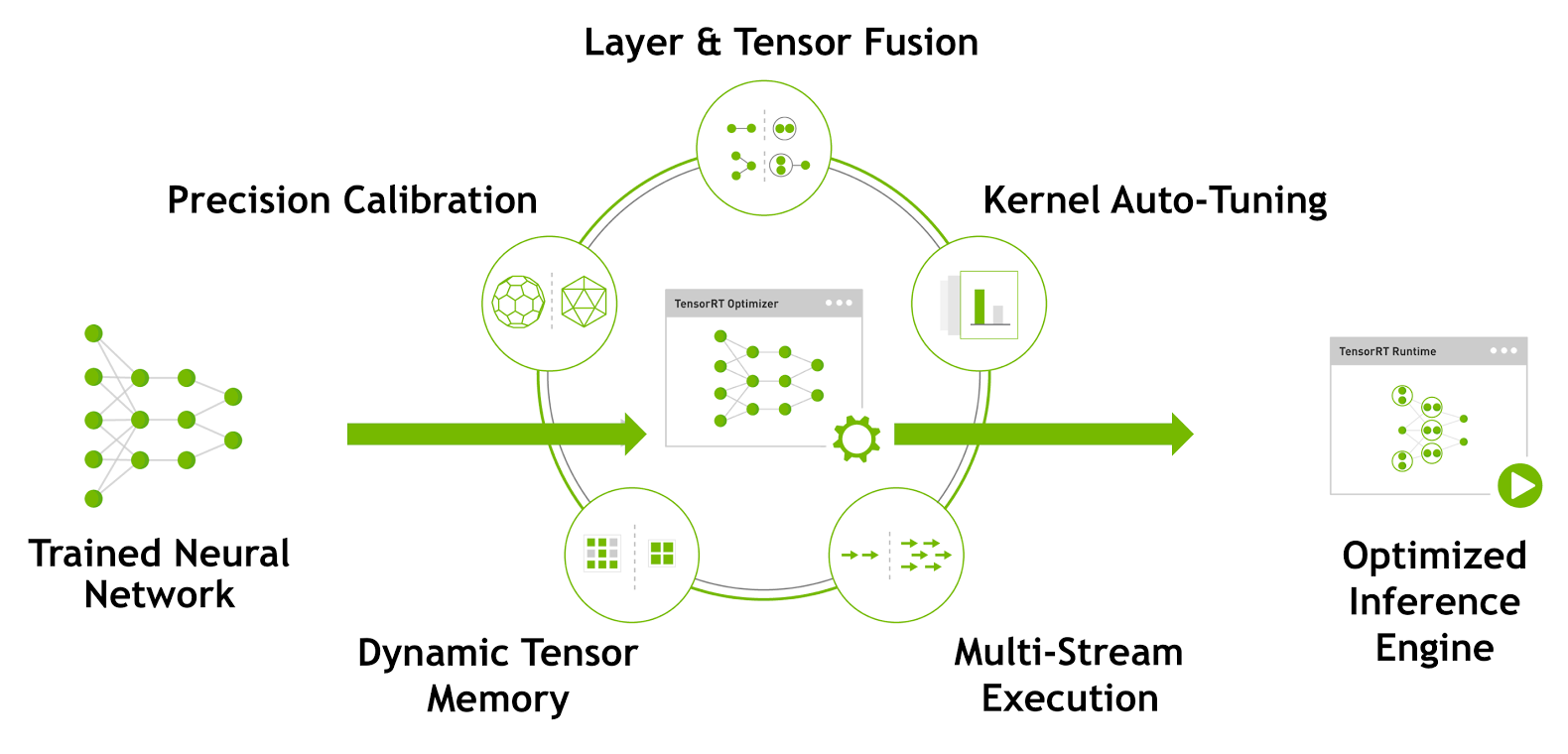
TensorRT is a high-performance deep learning inference optimizer and runtime engine for production deployment of deep learning applications. Developers can optimize models trained in TensorFlow or Caffe to generate memory-efficient runtime engines that maximize inference throughput, making deep learning practical for latency-critical products and services like autonomous driving..
The latest TensorRT 3 release introduces a fully-featured Python API, which enables researchers and developers to optimize and serialize their DNN using familiar Python code. With TensorRT 3 you can deploy models either in Python, for cloud services, or in C++ for real-time applications such as autonomous driving software running on the NVIDIA DRIVE PX AI car computer.
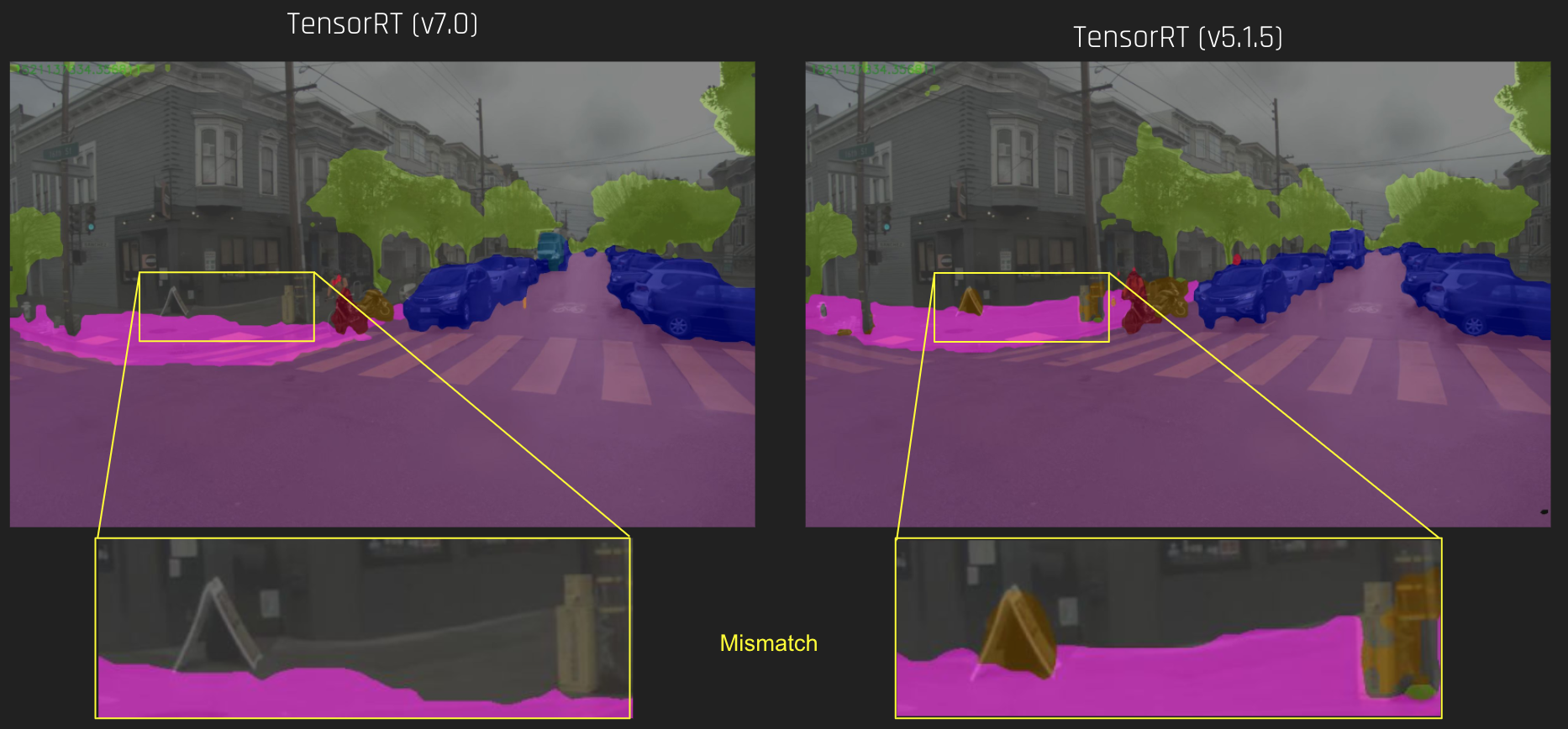
In a new NVIDIA Developer Blog post by Joohoon Lee, the lead of the Automotive Deep Learning Solutions Architect team at NVIDIA, shows you how to use the TensorRT 3 Python API on the host to cache calibration results for a semantic segmentation network for deployment using INT8 precision. The calibration cache then can be used to optimize and deploy the network using the C++ API on the DRIVE PX platform.
As a first step, optimizing the network using TensorRT using FP32 precision provides a good speedup. Just using TensorRT achieves an impressive 50% improvement over Caffe, but TensorRT can optimize the network further. By taking advantage of INT8 inference with TensorRT, TensorRT achieves nearly a 5x speedup, running the model in 50 ms latency and 20 images/sec on a single Pascal GPU of DRIVE PX AutoChauffeur, while maintaining the good accuracy of the original FP32 network.
Read more >
Fast INT8 Inference for Autonomous Vehicles with TensorRT 3
Dec 12, 2017
Discuss (0)

Related resources
- GTC session: Commercializing Mass-Produced Autonomous Driving Solutions
- GTC session: Commercializing Mass-Produced Autonomous Driving Solutions
- GTC session: Optimize Generative AI inference with Quantization in TensorRT-LLM and TensorRT
- GTC session: Optimize Generative AI inference with Quantization in TensorRT-LLM and TensorRT
- GTC session: Advancing Automotive AI With Large Language Models and Vision Language Models on NVIDIA DRIVE
- GTC session: Advancing Automotive AI With Large Language Models and Vision Language Models on NVIDIA DRIVE