The CUDA Refresher blog posts are authored by NVIDIA’s Pradeep Gupta, Director of the Solutions Architecture and Engineering team, with the goal of refreshing key concepts in CUDA, tools, and optimization for beginning or intermediate developers.
Part 1: Reviewing the Origins of GPU Computing
Scientific discovery and business analytics drive an insatiable demand for more computing resources. Many applications—weather forecasting, computational fluid dynamics simulations, and more recently machine learning and deep learning—need an order of magnitude more computational power than is currently available, with more complex algorithms that need more compute power to run.
The computing industry has relied on various ways to provide needed performance, such as increased transistor density, instruction-level parallelism, Dennard scaling, and so on
Read the full post on the NVIDIA Developer Blog.
Part 2: Getting started with CUDA
This is the second post in the CUDA Refresher series.
Advancements in science and business drive an insatiable demand for more computing resources and acceleration of workloads. Parallel programming is a profound way for developers to accelerate their applications. However, it has some common challenges.
The first challenge is to simplify parallel programming to make it easy to program. Easy programming attracts more developers and motivates them to port many more applications on parallel processors. The second challenge is to develop application software that transparently scales its parallelism to leverage the increasing number of processor cores with GPUs.
In this post, the team discusses how CUDA meets those challenges. They also lay out how to get started with installing CUDA.
Read the full post on the NVIDIA Developer Blog.
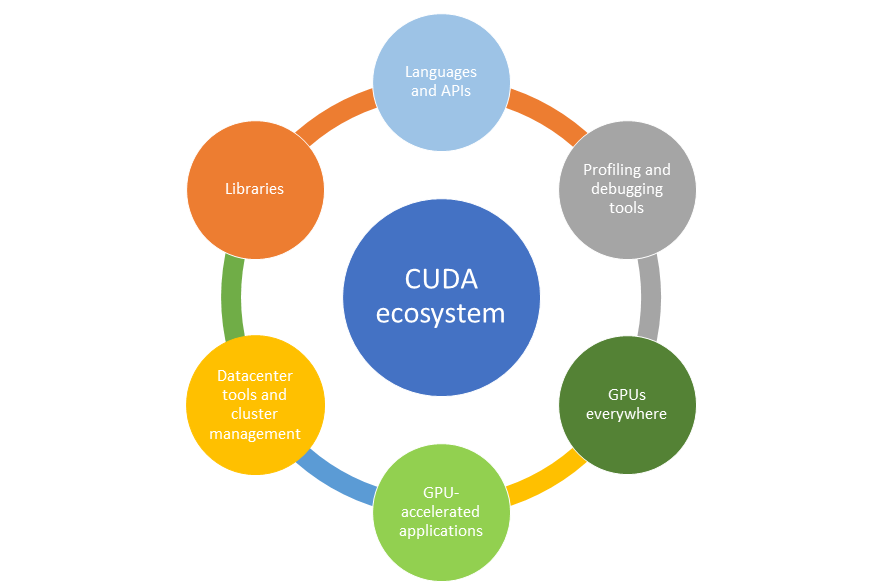
Part 3: The GPU Computing Ecosystem
This is the third post in the CUDA Refresher series.
Ease of programming and a giant leap in performance is one of the key reasons for the CUDA platform’s widespread adoption. The second biggest reason for the success of the CUDA platform is the availability of a broad and rich ecosystem.
Like any new platform, CUDA’s success was dependent on tools, libraries, applications, and partners available for CUDA ecosystem. Any new computing platform needs developers to port applications to a new platform. To do that, developers need state of art tools and development environments.
After applications start scaling, more tools are essential at the datacenter level. NVIDIA is committed to providing state-of-art tools and ecosystem services to developers and enterprises.
Read the full post on the NVIDIA Developer Blog.
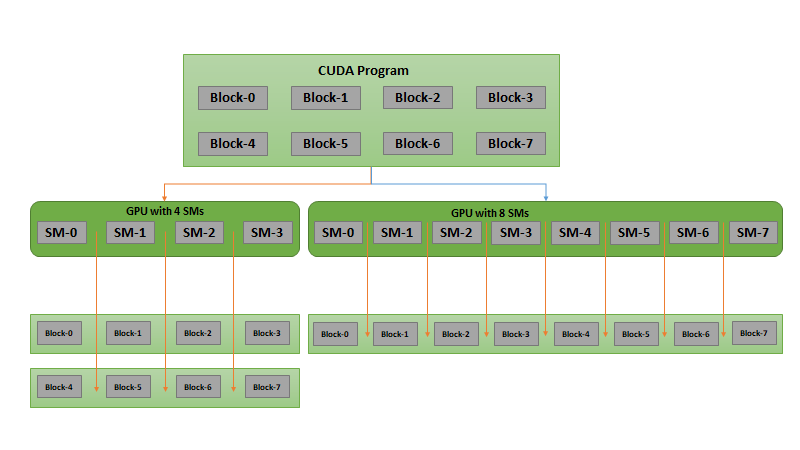
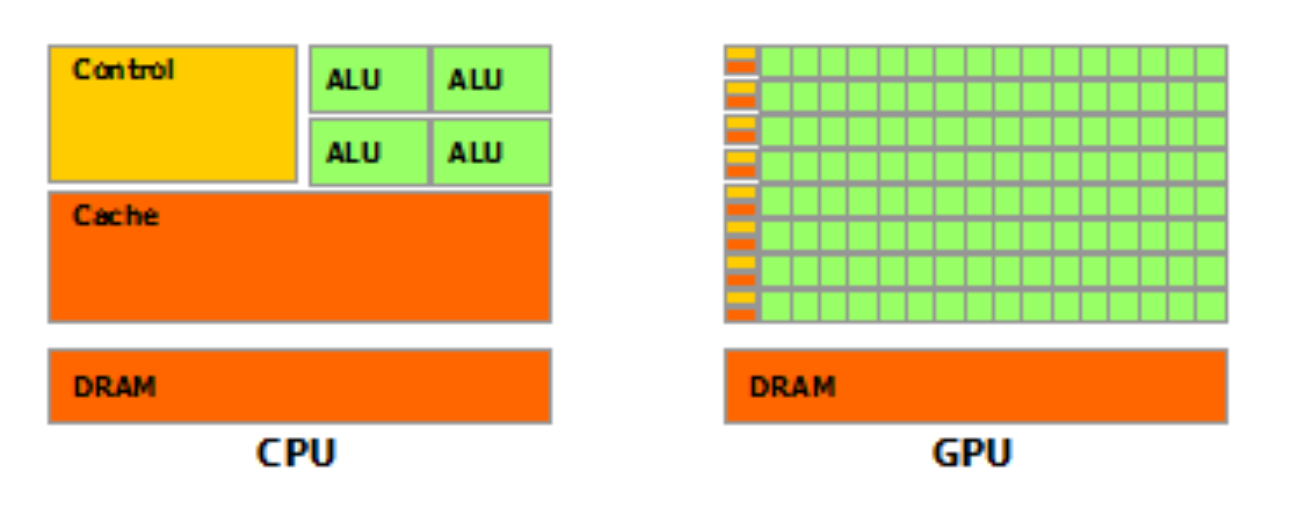
Part 4: The CUDA Programming Model
This is the fourth post in the CUDA Refresher series, which has the goal of refreshing key concepts in CUDA, tools, and optimization for beginning or intermediate developers.
The CUDA programming model provides an abstraction of GPU architecture that acts as a bridge between an application and its possible implementation on GPU hardware. This post outlines the main concepts of the CUDA programming model by outlining how they are exposed in general-purpose programming languages like C/C++.
Let me introduce two keywords widely used in CUDA programming model: host and device.
The host is the CPU available in the system. The system memory associated with the CPU is called host memory. The GPU is called a device and GPU memory likewise called device memory.
Read the full post on the NVIDIA Developer Blog.
About the Authors

Pradeep Gupta is Director of the Solutions Architecture and Engineering team at NVIDIA. He is responsible for running technical customer engagements for industries like autonomous driving, healthcare, and telecoms where AI is transforming many possible aspects of industry solutions. His focus is on building production-grade AI that can be deployed in life-critical systems. Previously, Pradeep worked in areas like high-performance computing, computer vision, mathematical library development, and data center technologies. He received a master’s degree in research from the Indian Institute of Science (IISc), Bangalore. His research focused on developing compute-efficient algorithms.