Recently the Allen Institute for Artificial Intelligence announced a breakthrough for a BERT-based model, passing a 12th-grade science test.
The GPU-accelerated system called Aristo can read, learn, and reason about science, in this case emulating the decision making of students. For this milestone, Aristo answered more than 90 percent of the questions on an eighth-grade science exam correctly, and 83 percent on a 12th-grade exam.
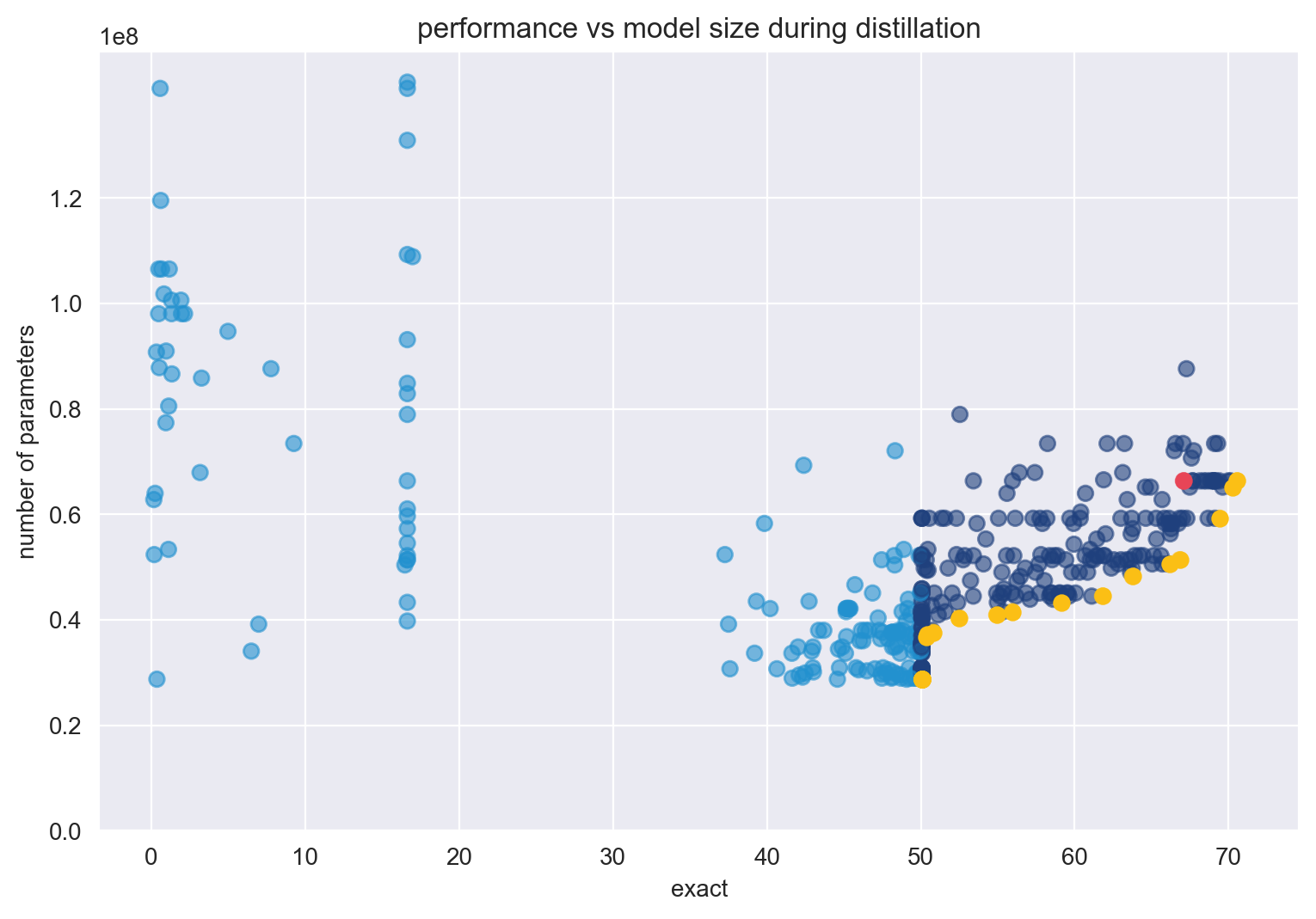
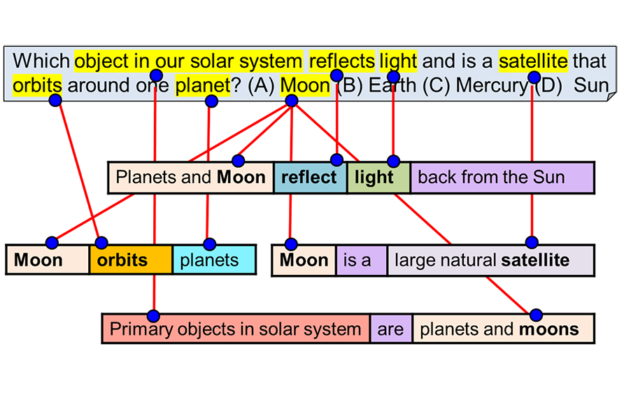
“Although Aristo only answers multiple choice questions without diagrams, and operates only in the domain of science, it nevertheless represents an important milestone towards systems that can read and understand,” the researchers stated in a newly published paper on ArXiv. “The momentum on this task has been remarkable, with accuracy moving from roughly 60% to over 90% in just three years,”
Though no diagrams were used for this particular task, the work as a whole integrates multiple AI-based technologies including natural language processing, information extraction, knowledge representation and reasoning, commonsense knowledge, and diagram understanding.
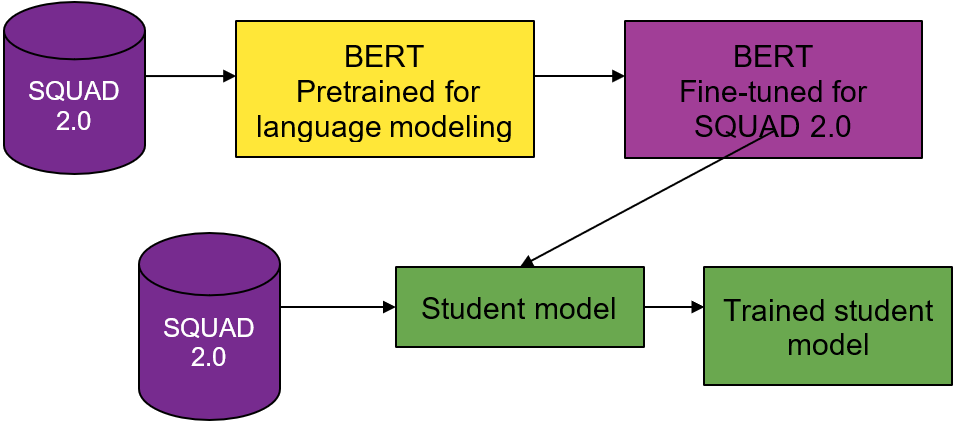
For the natural language processing models, the team relied on BERT. RoBERTa and ELMo as inspiration for developing their own BERT-based models named AristoBERT and AristoRoBERTa.
“The AristoBERT solver uses three methods to apply BERT more effectively. First, we retrieve and supply background knowledge along with the question when using BERT. This provides the potential for BERT to “read” that background knowledge and apply it to the question, although the exact nature of how it uses background knowledge is more complex and less interpretable,” the researchers stated in their paper. “Second, we fine-tune BERT using a curriculum of several datasets, including some that are not science related. Finally, we ensemble different variants of BERT together.”
To train the models, the team relied on NVIDIA P100 GPUs on the Google Cloud, using the organization’s Beaker.org research platform, as well as the AllenNLP research library, an open source PyTorch-based framework for developing state-of-the-art deep learning models on a wide variety of linguistic tasks.
For some experiments requiring more memory, the team relied on an in-house server powered by NVIDIA Quadro RTX 8000 GPUs.
Training data consisted of over 100,000 exam questions from multiple datasets including the RACE training set, OpenBookQA, ARC-Easy, ARC-Challenge, 22 Regents Living Environment exams and others.
Using three variants of BERT, BERT-large-cased, BERT-large-uncased, and BERT-large-cased-whole-word-masking the team developed their own variants.
“These systems are trained to apply relevant background knowledge to the question, and use a small training curriculum to improve their performance. Their high performance reflects the rapid progress made by the NLP field as a whole,” the Allen Institute researchers stated.
To help improve adoption of BERT-based models and improve the field as a whole, the Allen Institute team has released several datasets and published accompanying leaderboards, encouraging other developers to try and build on the work.
The team notes that although an important milestone, the work is only a step on the long road towards a system that can perform deep understanding of science, one that can answer multiple choice questions, as well as generating short and long answers to direct questions, discussing the work with a user, and correcting misunderstandings after being informed by experts.
“These are all ambitious tasks still largely beyond the current technology, but with the rapid progress happening in NLP and AI, solutions may arrive sooner than we expect,” the researchers stated.
A paper describing the work was published this week on ArXiv. The announcement from the Allen Institute first appeared on the New York Times this week.