Researchers from Johns Hopkins University and Amazon published a new paper describing how they trained a deep learning system that can help Alexa ignore speech not intended for her, improving the speech recognition model by 15%.
“Voice-controlled house-hold devices, like Amazon Echo or Google Home, face the problem of performing speech recognition of device directed speech in the presence of interfering background speech,” the researchers stated in their paper.
To achieve this, the researchers trained a neural network to match and recognize the subsequent speech of whoever utters the “wake word” – usually ‘Alexa’ – and to ignore interfering speech from other people or media.
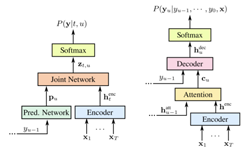
“The challenge of this task is to learn a speaker representation from a short segment corresponding to the anchor word,” the researchers said. “We implemented our technique using two different neural-network architectures. Both were variations of a sequence-to-sequence encoder-decoder network with an attention mechanism,” the researchers said.
Using NVIDIA V100 GPUs with the OpenSeq2Seq toolkit for distributed and mixed precision training of sequence-to-sequence models, built using TensorFlow, the team trained their algorithm on 1,200 hours of live data in English from Amazon Echo.

By modifying the baseline network developed, the team added an additional input that augments the attention mechanism by prioritizing speech similar to the anchor word. “During training, the attention mechanism automatically learns which acoustic characteristics of the wake word to look for in subsequent speech,” the team included.
The team also developed a mask-based model that more explicitly matches the input speech with the acoustic profile of the anchor word.
In the end, the first approach performed better, achieving the 15% improvement, while the second model only achieved a 13% improvement.
The algorithm uses NVIDIA GPUs for both training and inference, the researchers said.
You can learn more by reading the paper.