The human brain contains around 86 billion neurons and imaging a single cubic millimeter of it can generate more than 1000 terabytes of data. Because of the sheer size, the process of mapping the internal structure of the nervous system is computationally intensive and tedious. To accelerate the process, researchers from Google and the Max Planck Institute of Neurobiology in Germany developed a deep learning-based system that can automatically map the brain’s neurons.
“The primary bottleneck in brain mapping has been automating the interpretation of these data, rather than the acquisition of the data itself,” the researchers wrote in a blog post. “[We] show how a new type of recurrent neural network can improve the accuracy of automated interpretation of connectomics data by an order of magnitude over previous deep learning techniques.”
Using NVIDIA Tesla GPUs and the cuDNN-accelerated TensorFlow deep learning framework, the team trained their recurrent neural network on thousands of 2D images showing a slice of the brain. When the images are stacked on top of another, they generate a 3D image.
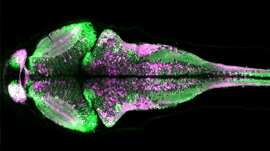
Reconstruction of a portion of zebra finch brain. Colors denote distinct objects in the segmentation that was automatically generated using a flood-filling network. Gold spheres represent synaptic locations automatically identified using a previously published approach.
The Google team estimates that it would have taken 100,000 hours to label the entire sample, which was only for a 1mm cube. Meanwhile, the AI trained and completed the task in seven days.
The researchers say their algorithm is ten times more accurate than previous automated approaches.
“We used ERL (a metric devised by the team that stands for expected run length) to measure our progress on a ground-truth set of neurons within a 1-million cubic micron zebra finch song-bird brain imaged by our collaborators using serial block-face scanning electron microscopy and found that our approach performed much better than previous deep learning pipelines applied to the same dataset.
The team is making the code available on GitHub. In future projects, the team will take the data from the brain to determine how it learns to sing.
Read more >
AI Helps Unlock the Mysteries of the Brain
Jul 16, 2018
Discuss (0)
Related resources
- DLI course: Building a Brain in 10 Minutes
- GTC session: How AI Will Decode Biology to Radically Improve Lives
- GTC session: How Artificial Intelligence is Powering the Future of Biomedicine
- GTC session: Fireside Chat with Yoav Shoham and Vartika Singh: Going Beyond LLMs, the Future of AI That Understands
- NGC Containers: MATLAB
- Webinar: Accelerate AI Model Inference at Scale for Financial Services