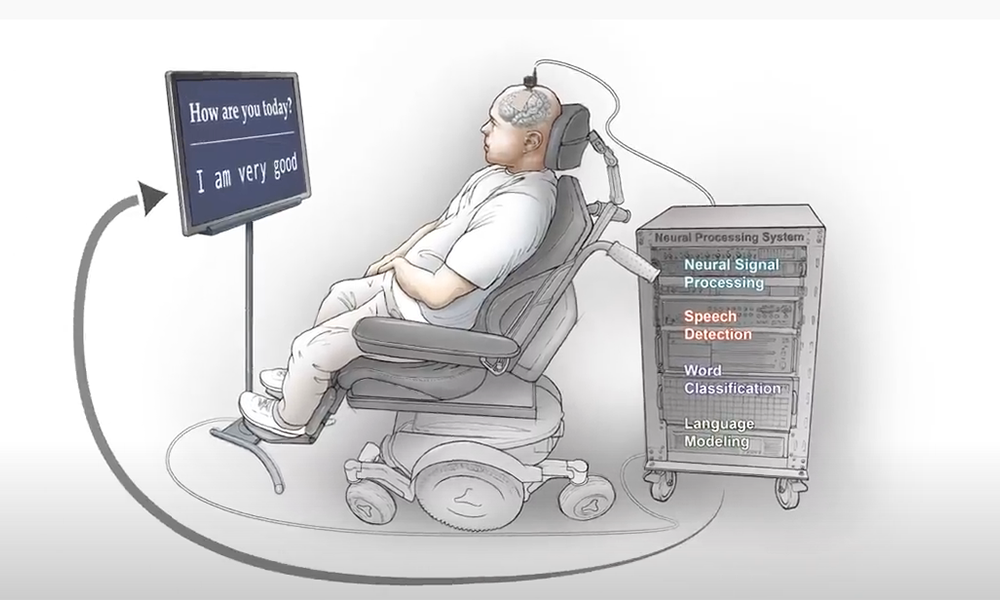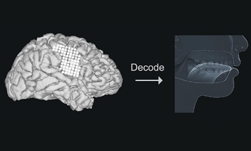
To help people who have lost the ability to speak, researchers from the University of California, San Francisco developed a deep learning method that can decode and convert brain signals into speech.
“Neurological conditions that result in the loss of communication are devastating,” the researchers wrote in their paper. “Technology that translates neural activity into speech would be transformative for people who are unable to communicate as a result of neurological impairments,”
Current methods for recreating speech are extremely cumbersome and inefficient. A common approach allows some patients to write their thoughts by letter, however, it can only reproduce about 10 words per minute. For comparison, an average speaker can recite around 150 words per minute.
To develop a proof of principle, the team captured high-density electrocorticographic signals from five participants who underwent intracranial monitoring for epilepsy.

Researchers implanted electrodes similar to these in participants’ skulls to record their brain signals.
Using NVIDIA Tesla GPUs the team then trained a recurrent neural network with the cuDNN-accelerated Keras and TensorFlow deep learning frameworks, on the sound of the participants speaking several hundreds of sentences aloud, along with the cortical signals.
The algorithm associated the patterns captured with the subtle movement of the patient’s lips, tongue, larynx, and jaw.
The algorithm is trained using the ADAM optimizer. For the first stage of training a batch size of 256 was used and in the second batch size of 25.

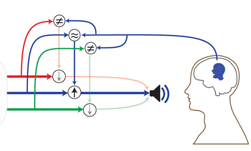
a, The neural decoding process begins by extracting relevant signal features from high-density cortical activity. b, A bLSTM neural network decodes kinematic representations of articulation from ECoG signals. c, An additional bLSTM decodes acoustics from the previously decoded kinematics. Acoustics are spectral features (for example, MFCCs) extracted from the speech waveform. d, Decoded signals are synthesized.
According to the researchers, the decoder was optimized for decoding acoustics directly from the electrodes. With as little as 25 minutes of speech, the team achieved satisfactory performance and performance continued to increase with more data.
To synthesize the speech from the acoustic features, the team used an implementation of the Mellog spectral approximation algorithm within Festvox, a tool maintained by researchers at Carnegie Mellon University’s speech group.
For inference, the team developed a model that used the GPUs to infer articulatory kinematics from the audio recordings. Ax explained in the paper, the model is comprised of a stacked deep encoder decoder network, in which the encoder combines phonological and acoustic representations into an articulatory representation. That information is then used to reconstruct the speech, the researchers explained.
“For the first time, this study demonstrates that we can generate entire spoken sentences based on an individual’s brain activity,” said Edward Chang, a professor of neurological surgery and member of the UCSF Weill Institute for Neuroscience. “This is an exhilarating proof of principle that with technology that is already within reach, we should be able to build a device that is clinically viable in patients with speech loss.”
The scientists say their technology isn’t yet accurate for use outside the lab, however, it can synthesize whole sentences. When tested on 101 different people, 70% of them understood the words uttered.
The research was recently published in the Journal Nature. The work paves the way for stroke survivors, Parkinson’s disease patients, and many others to more efficiently communicate.